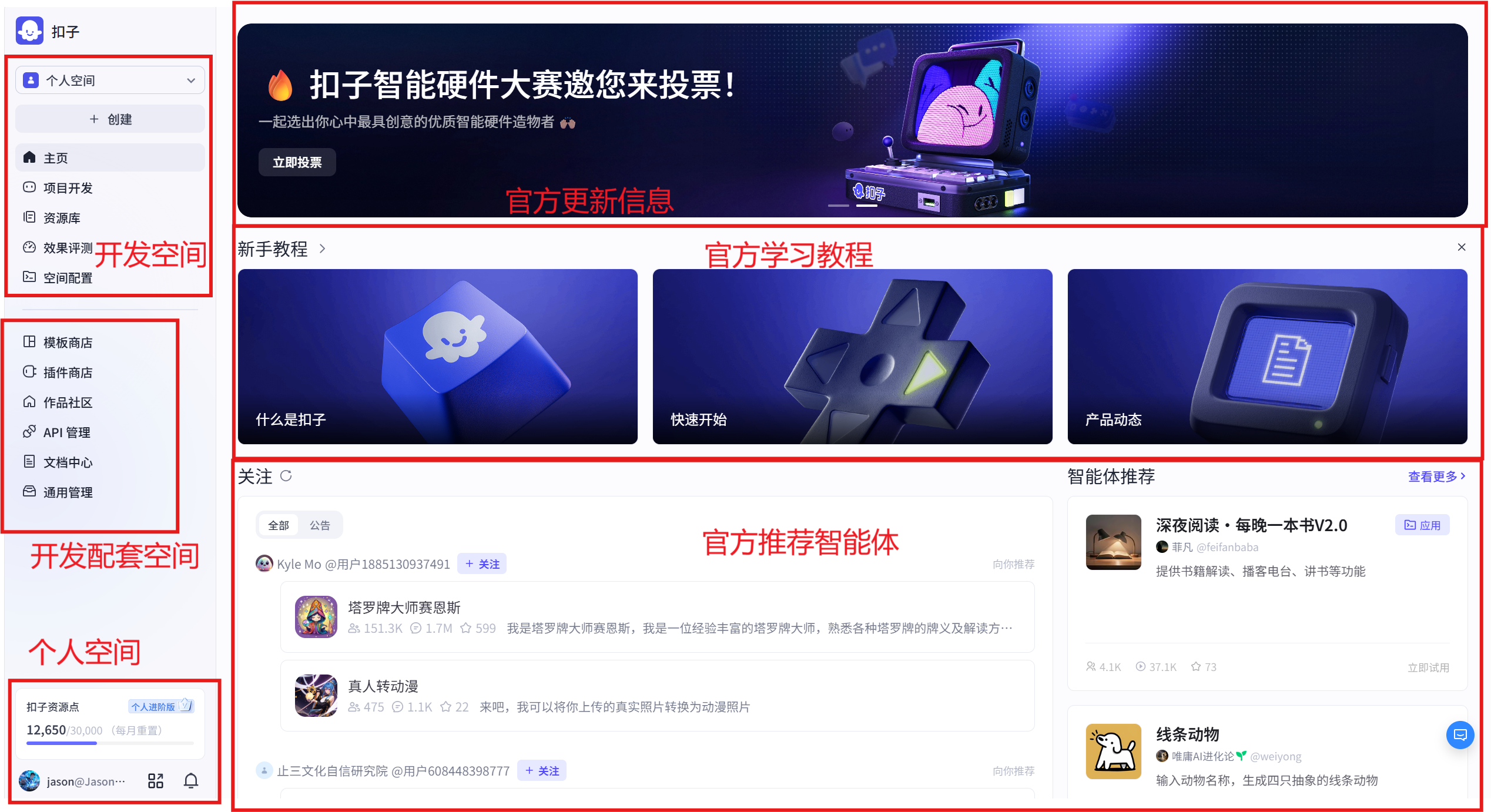
图 5.1 扣子智能智能体平台整体示意图
图 5.1 扣子智能智能体平台整体示意图
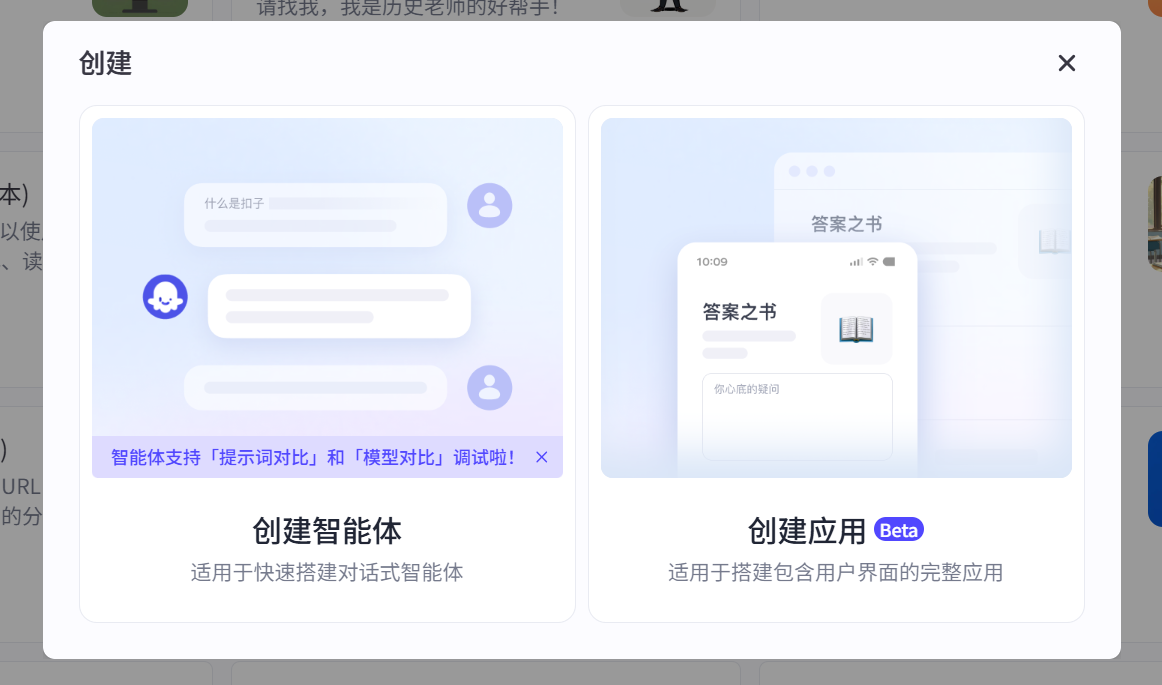
图 5.2 扣子智能体创建入口
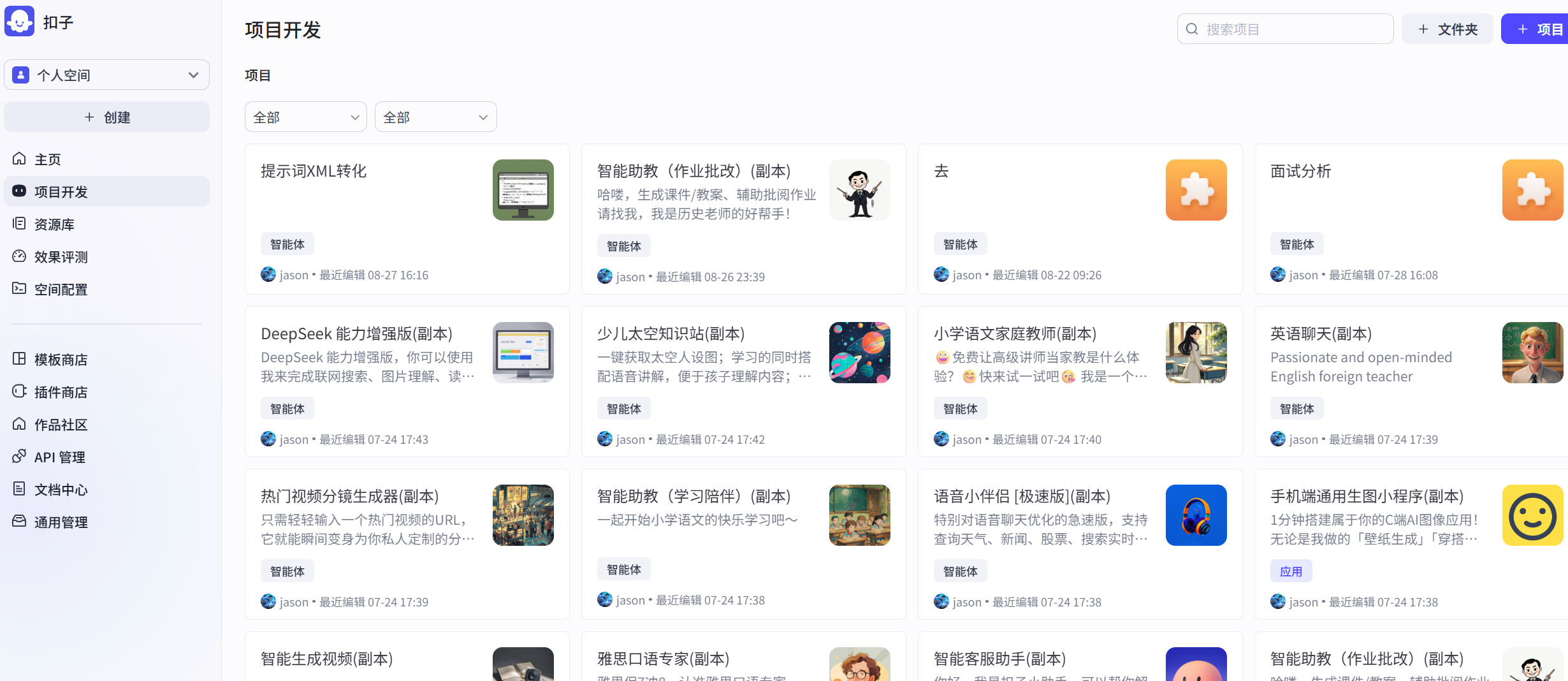
图 5.3 扣子智能体项目空间
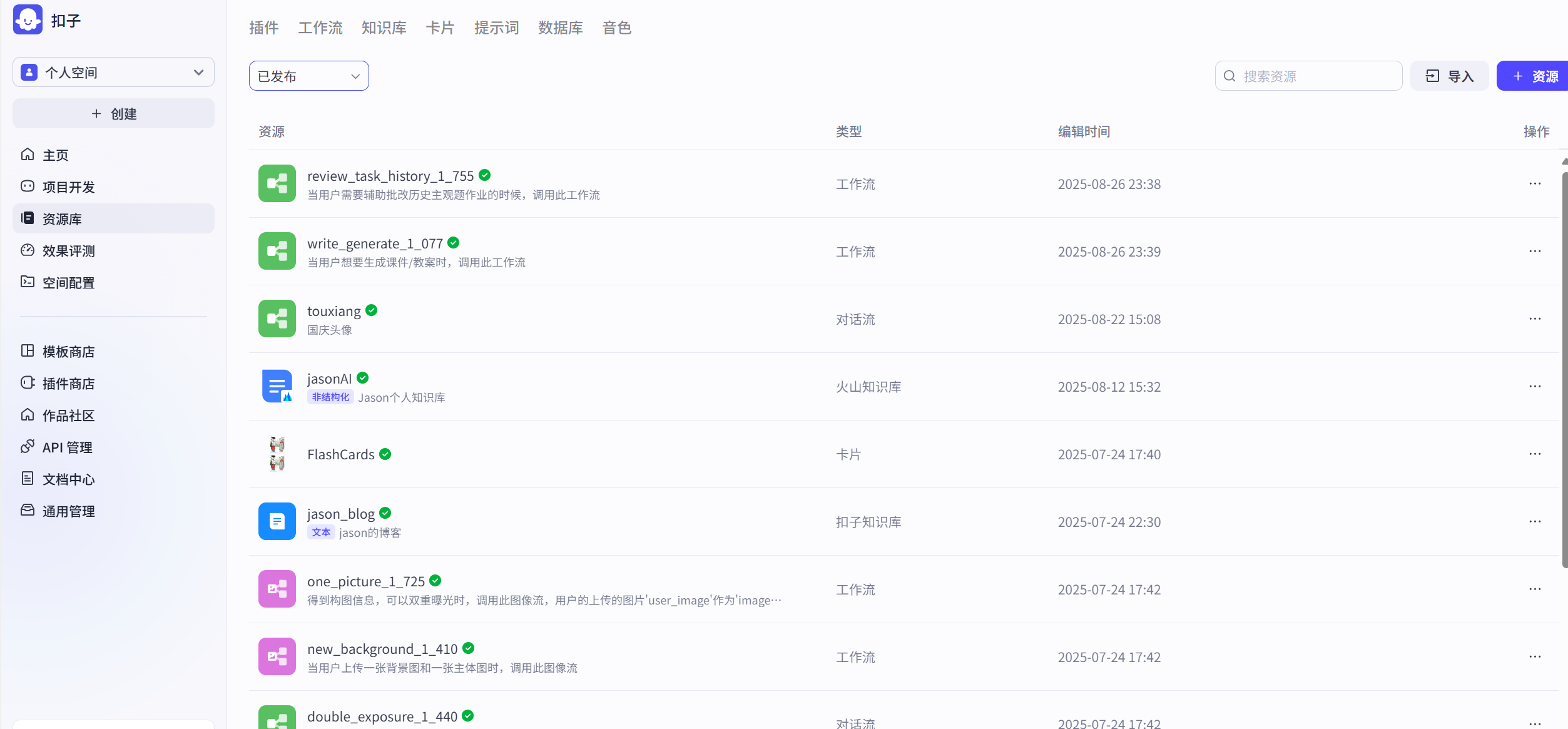
图 5.4 扣子智能体资源库
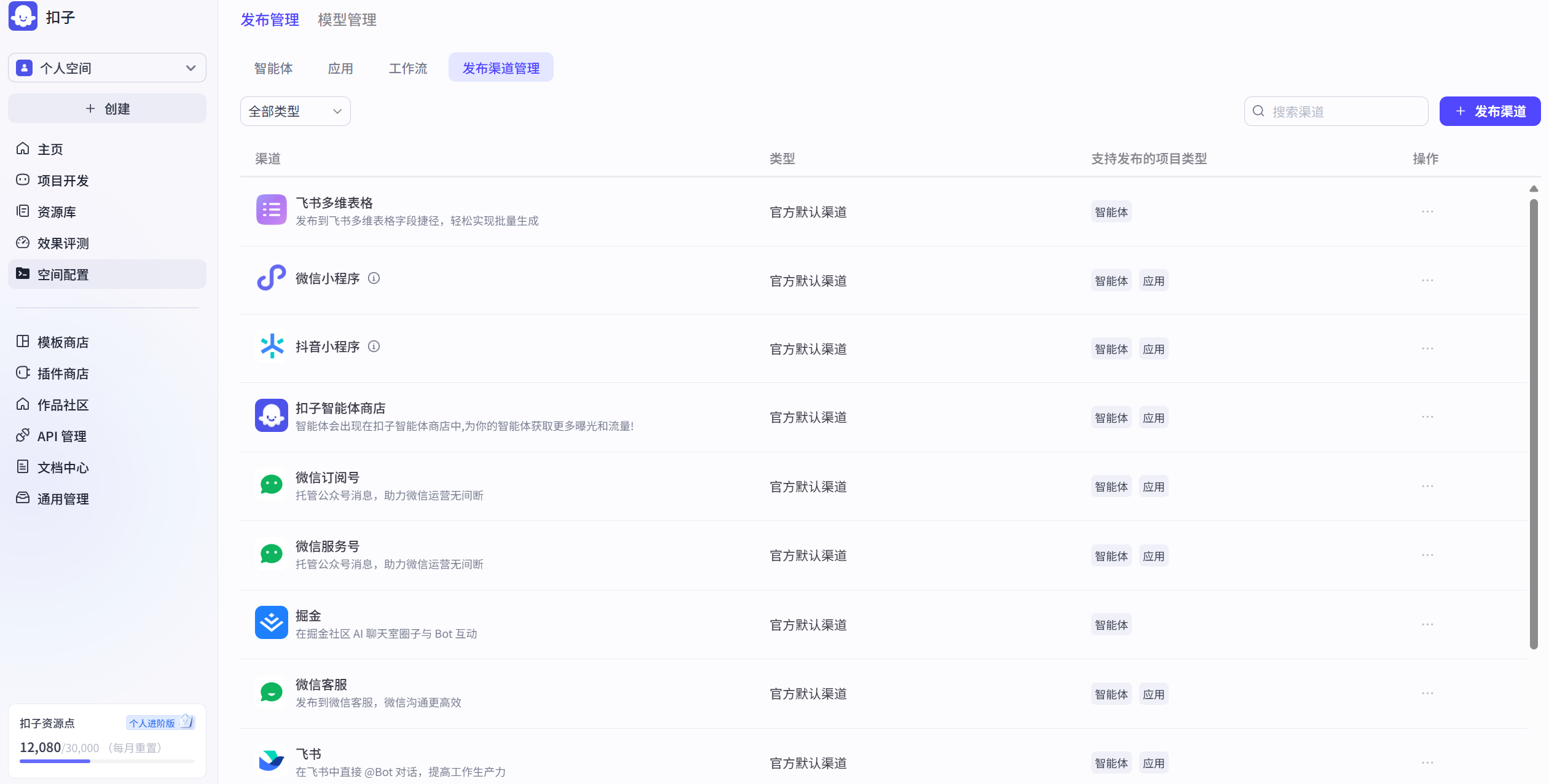
图 5.5 扣子智能体发布渠道
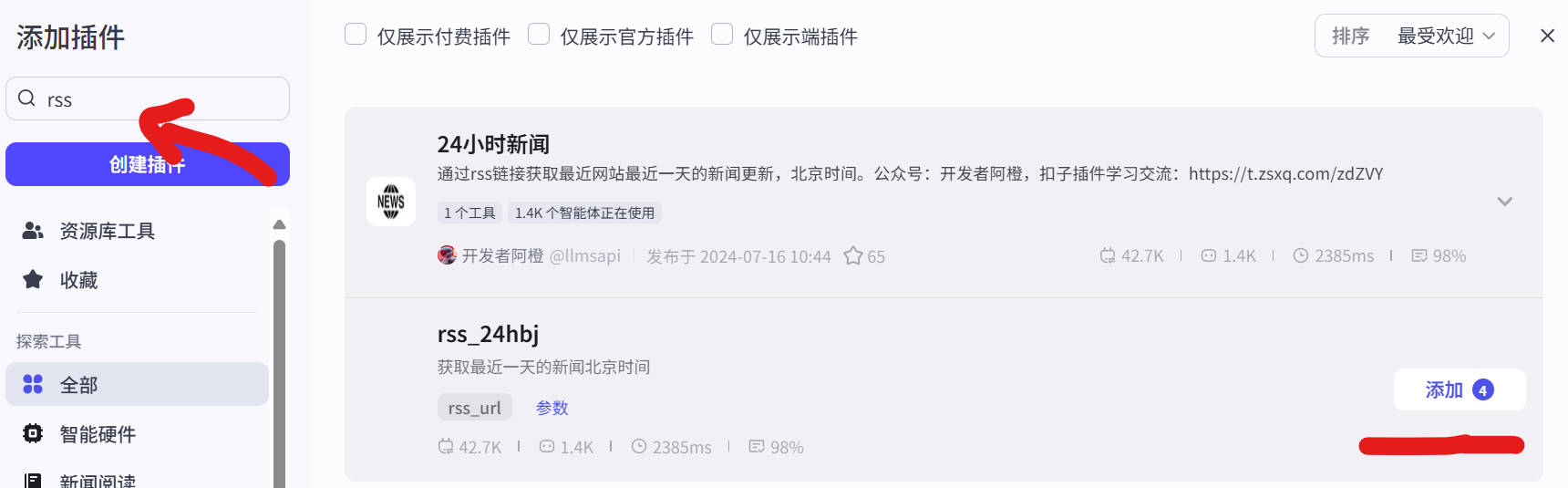
图 5.6 媒体平台的RSS源插件
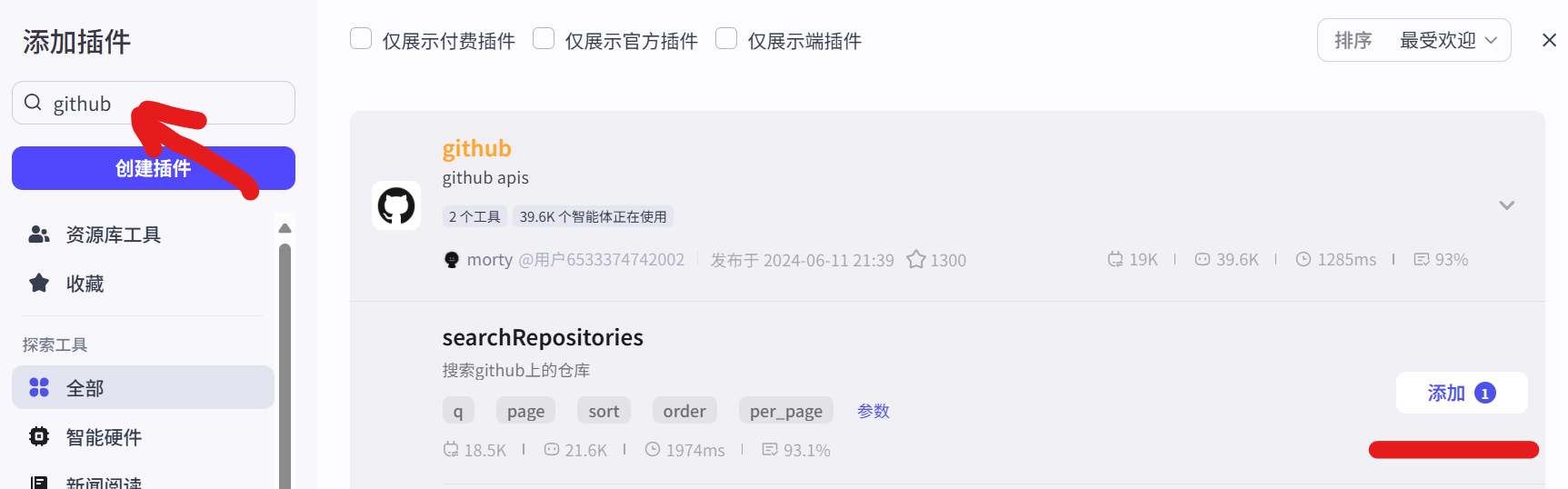
图 5.7 GitHub插件
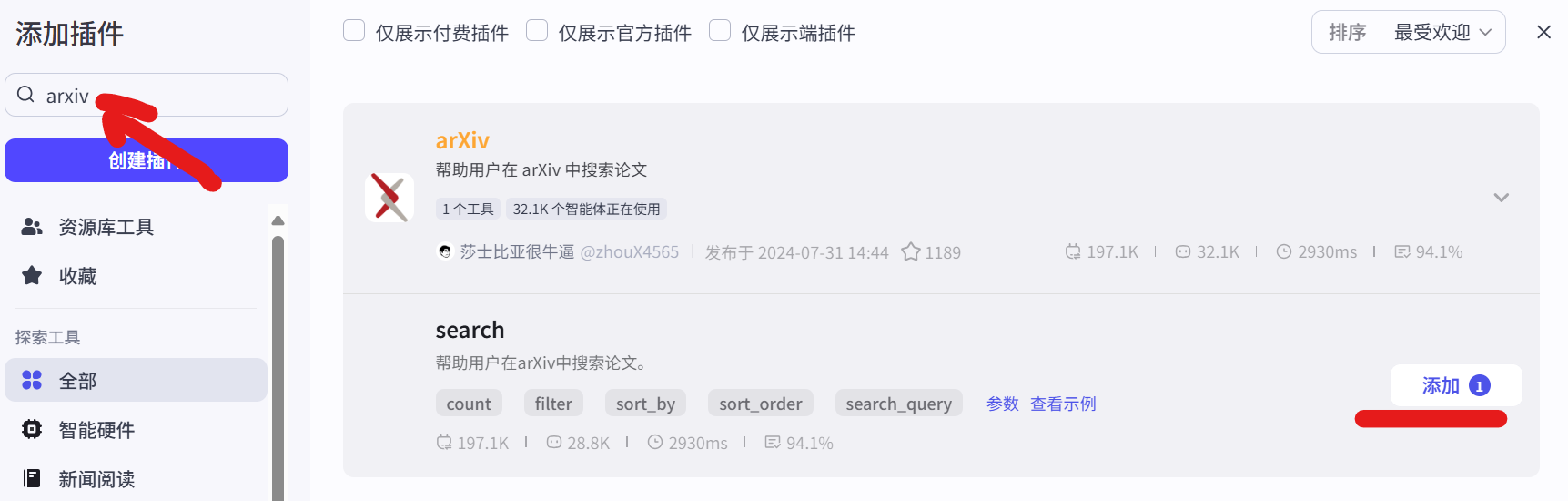
图 5.8 Arxiv插件
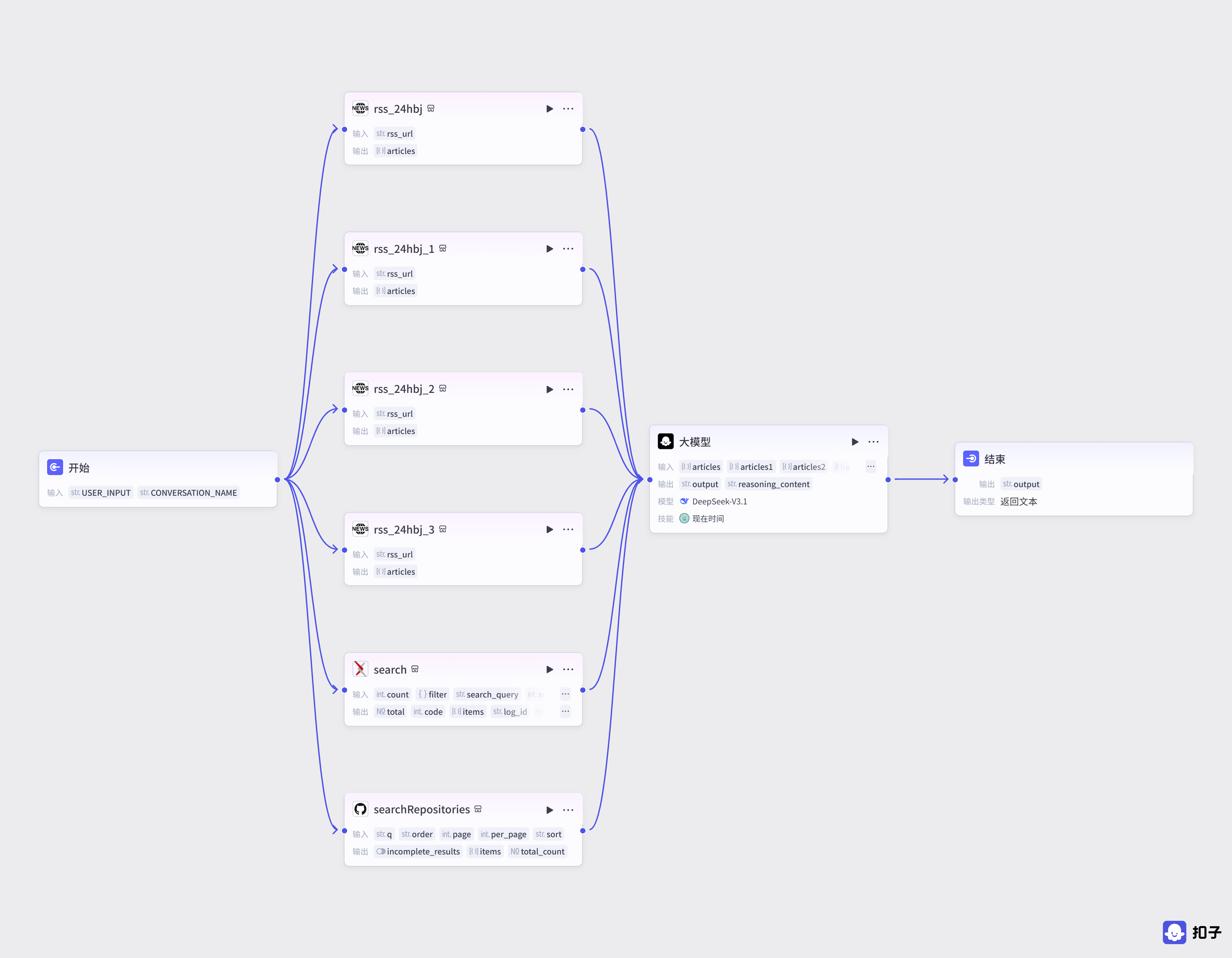
图 5.9 每日AI简报编排流程图
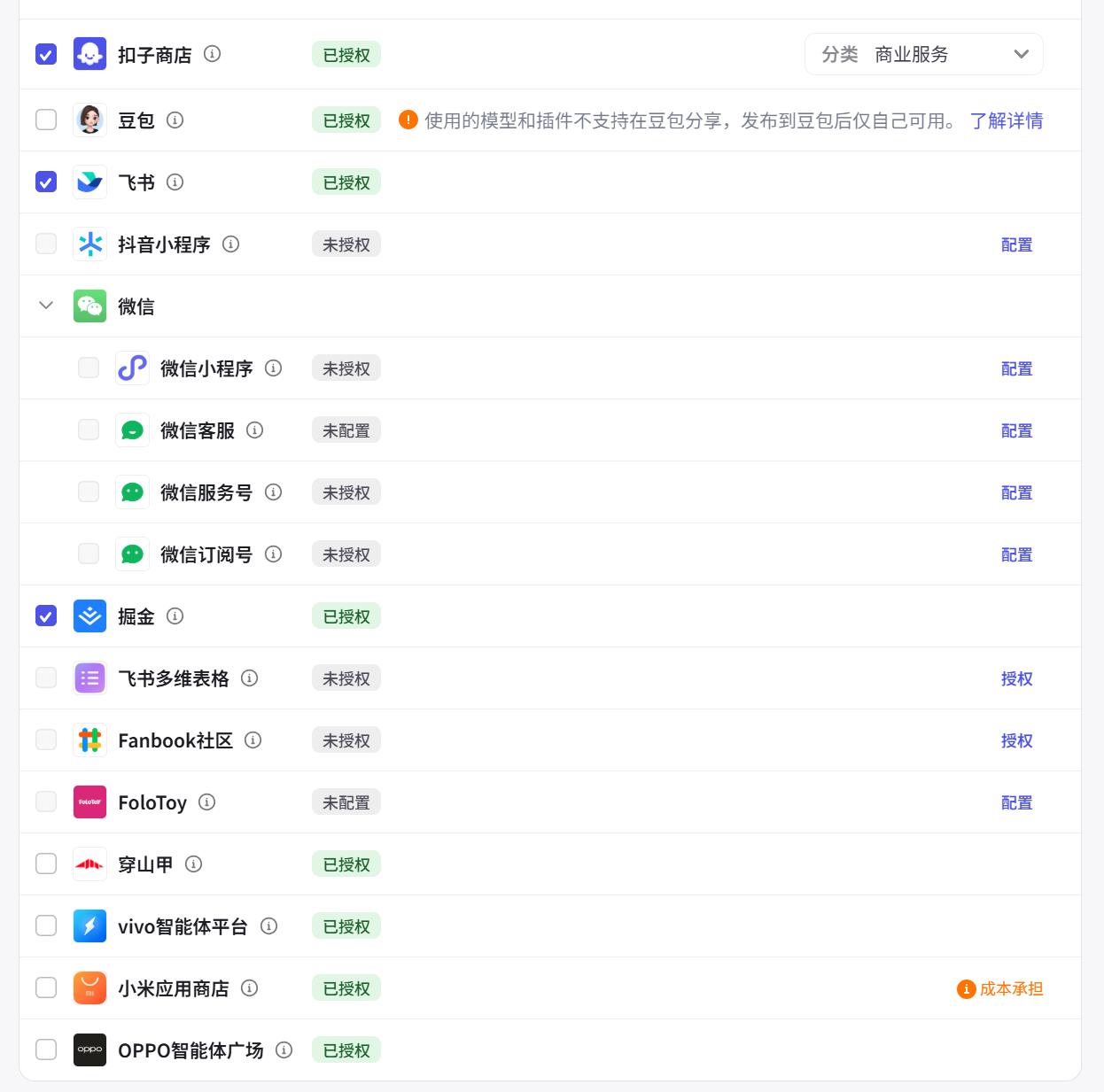
图 5.10 扣子平台的多元发布渠道
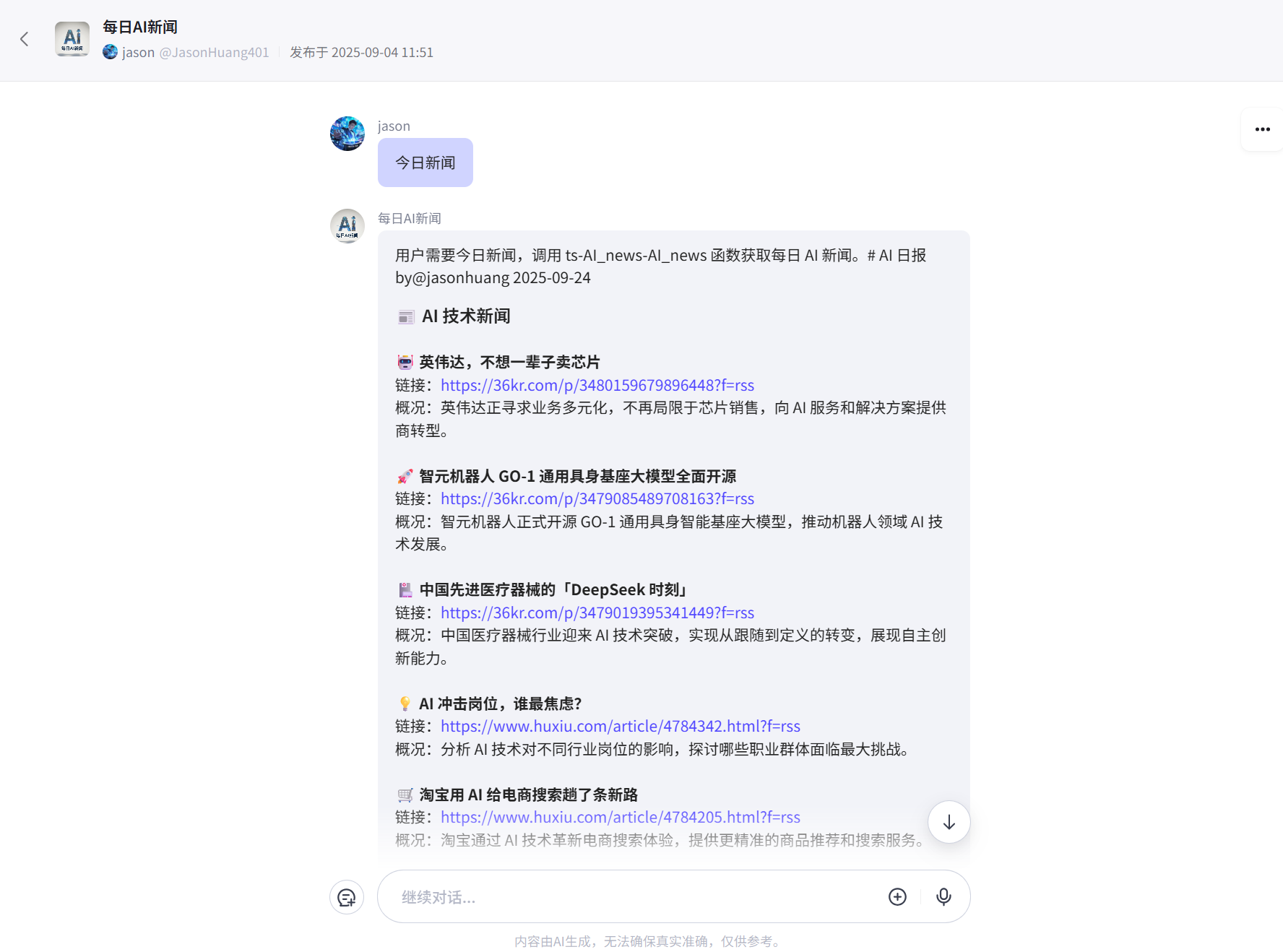
图 5.11 AI智能体-每日AI新闻
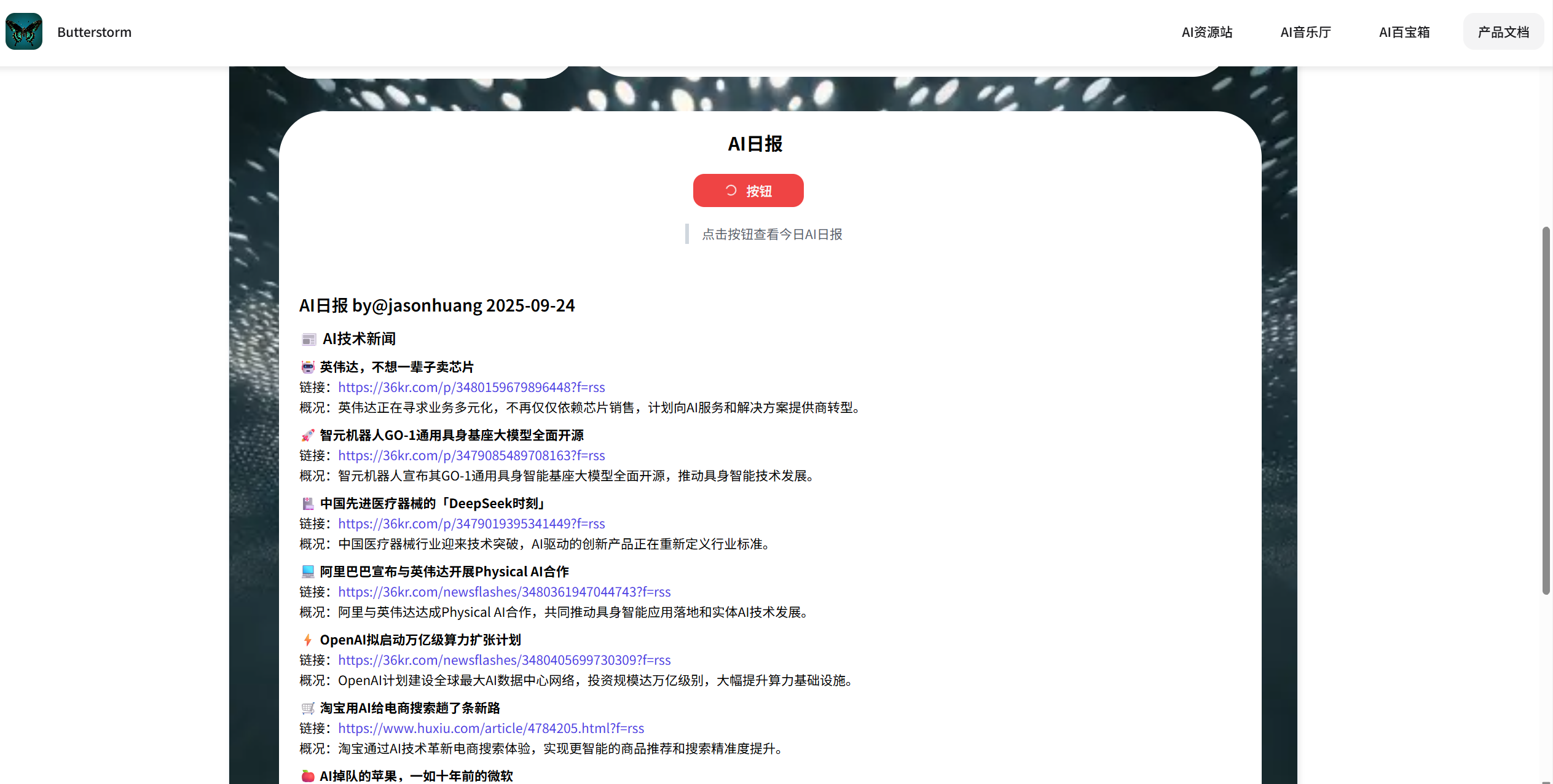
图 5.12 AI应用中的每日AI新闻
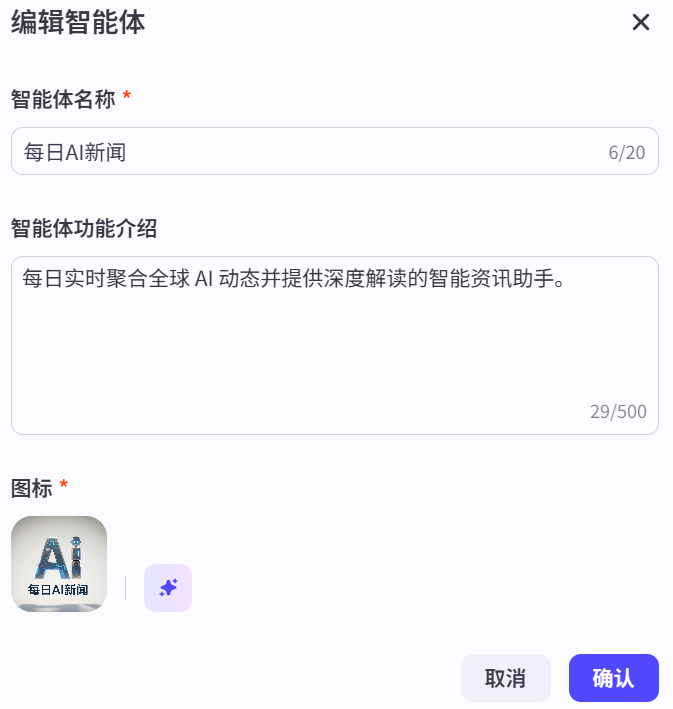
图 5.13 为智能体配置基础信息
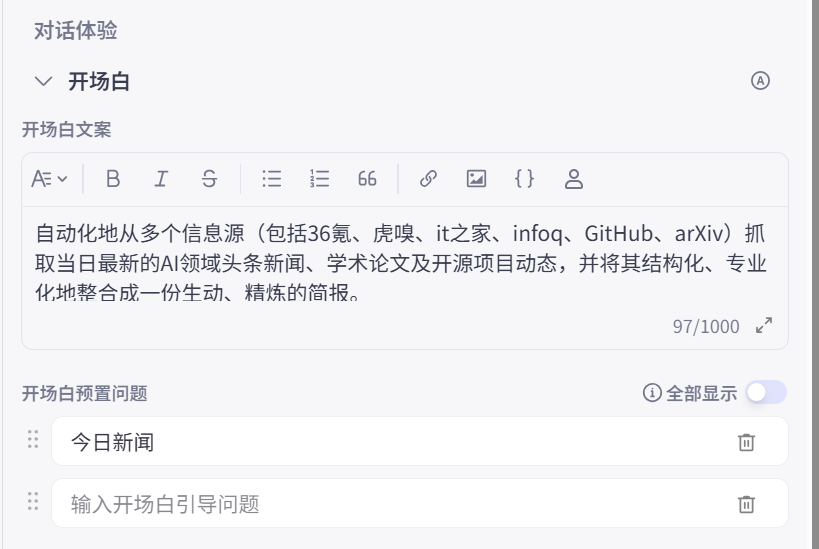
图 5.14 为智能体配置开场白和预设问题
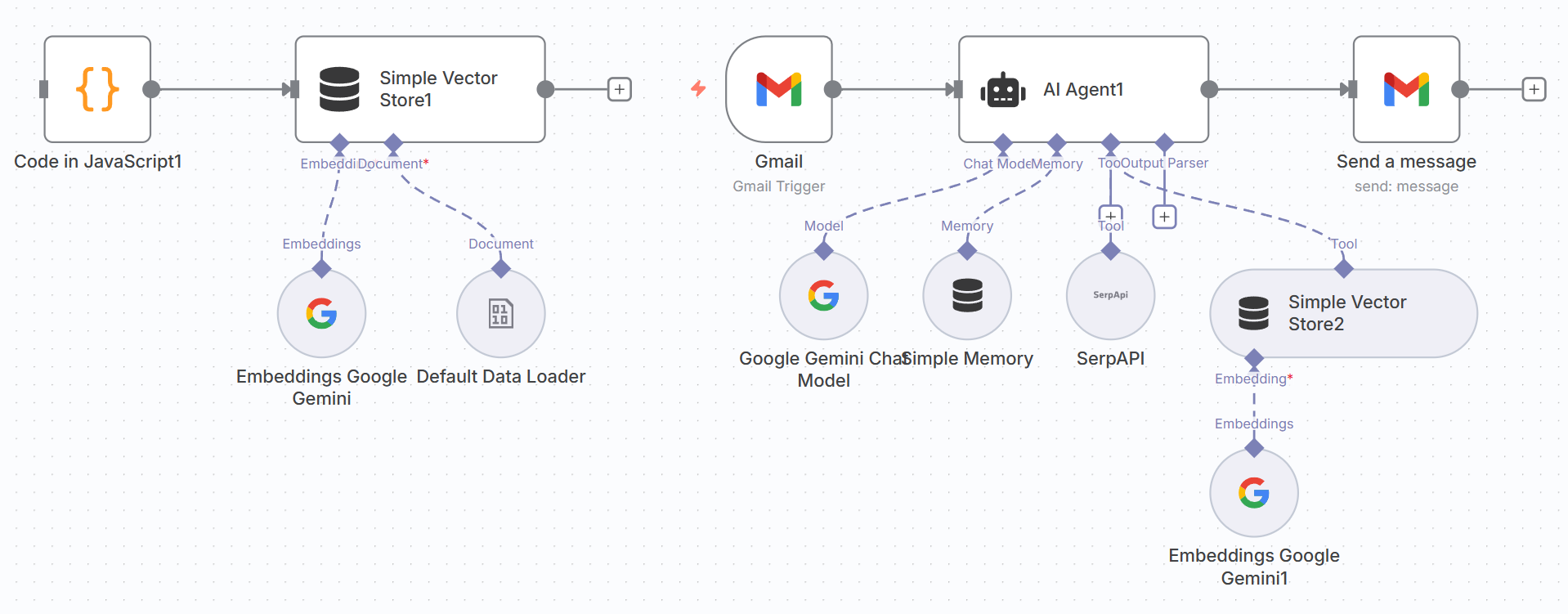
图 5.X 一体化智能邮件 Agent 架构示意图
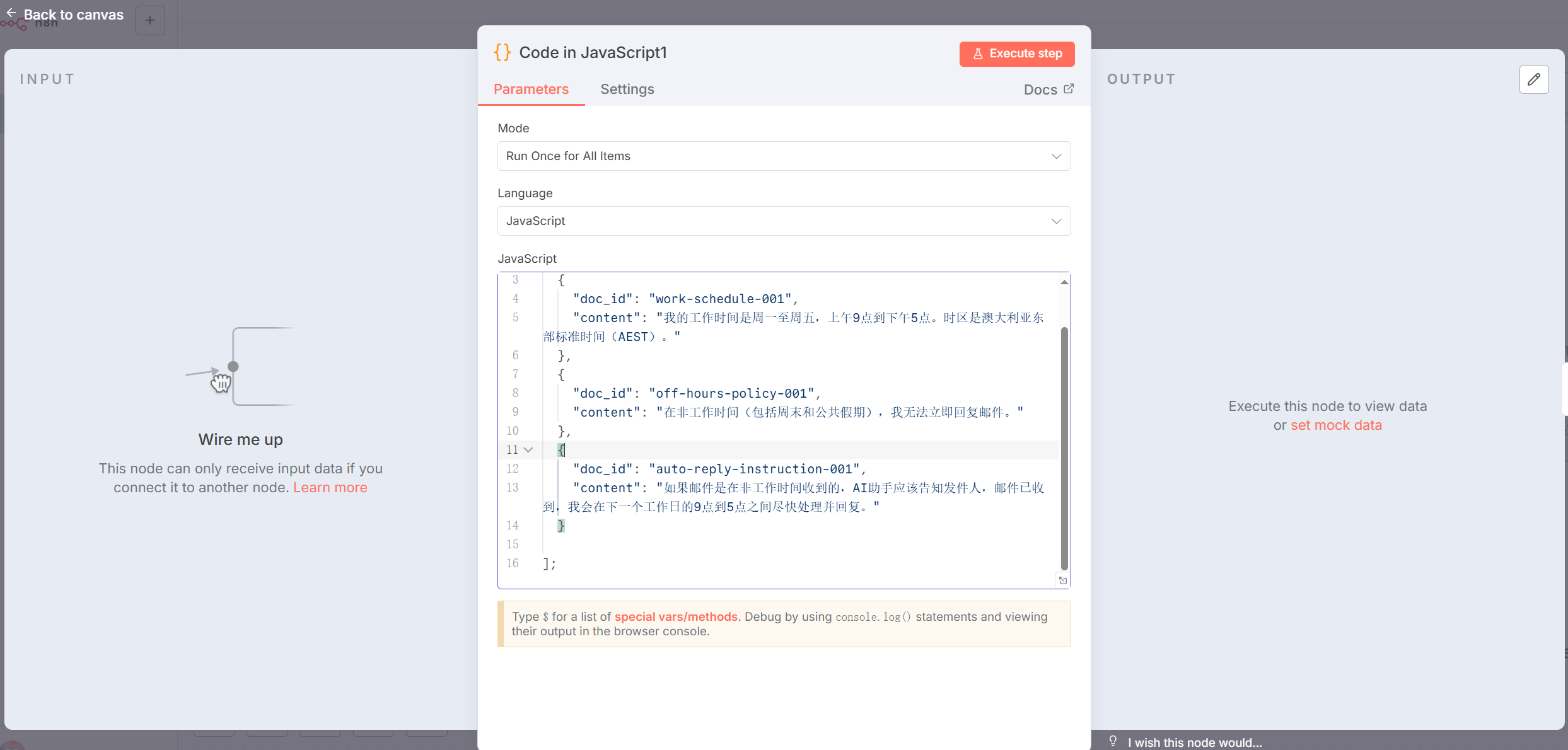
图 5.X 在 Code 节点中定义知识源
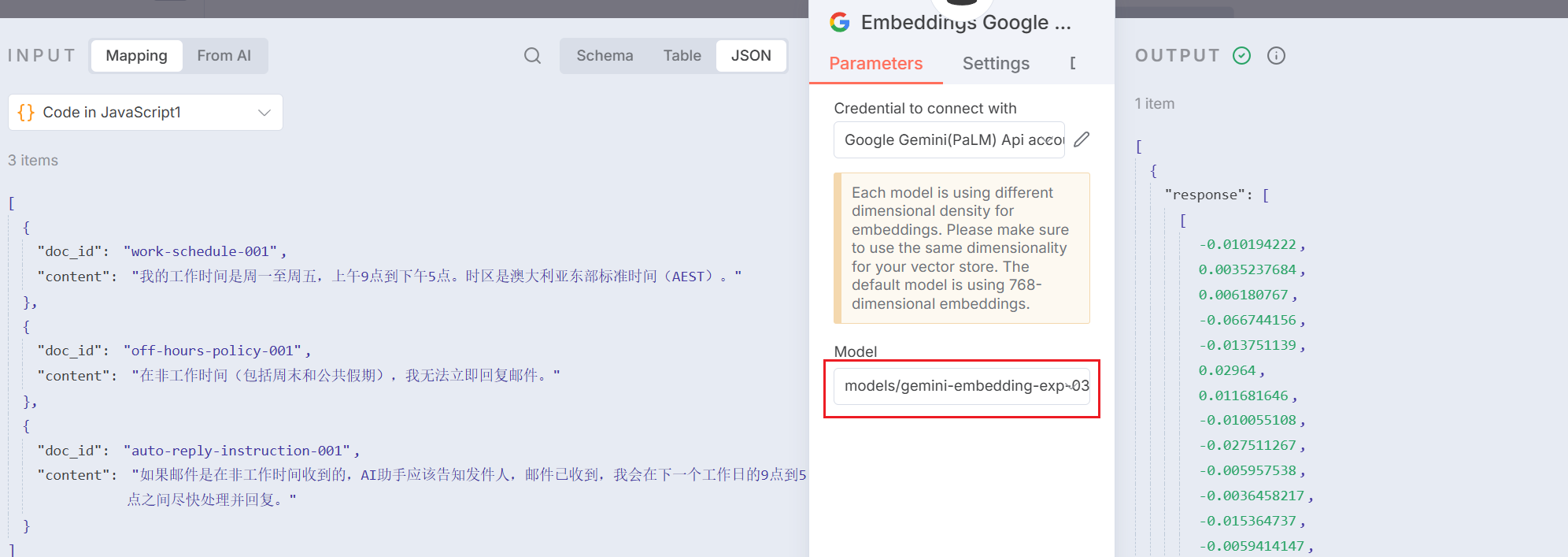
图 5.X 对 Code 中数据进行向量化
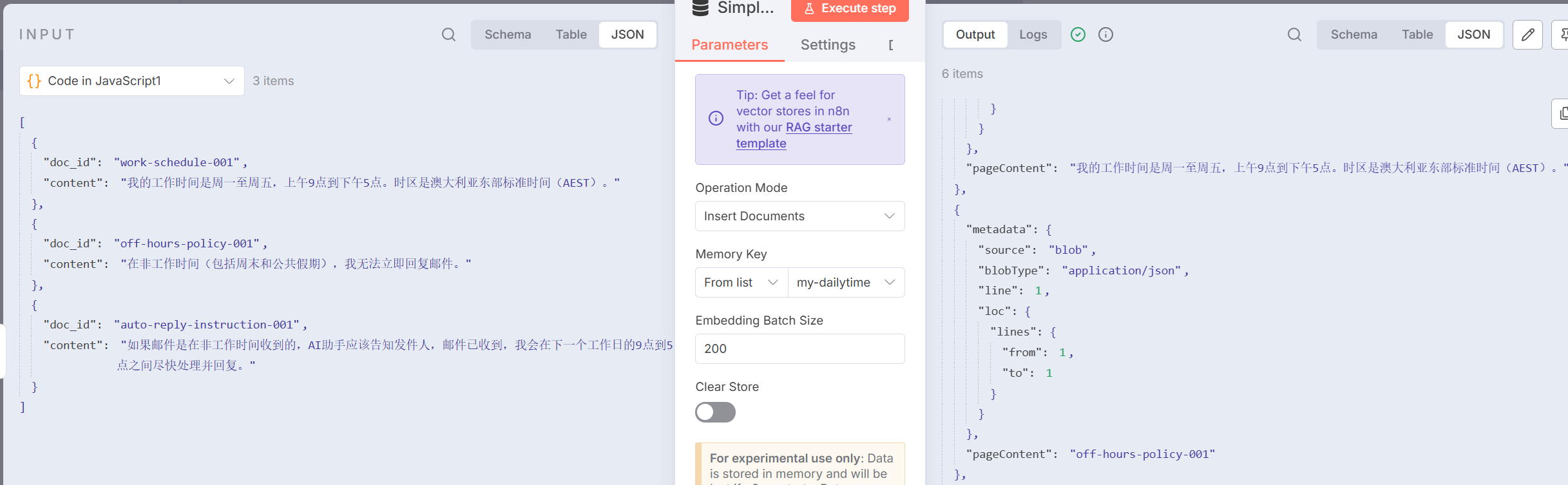
图 5.X 对 Code 中数据存入向量存储
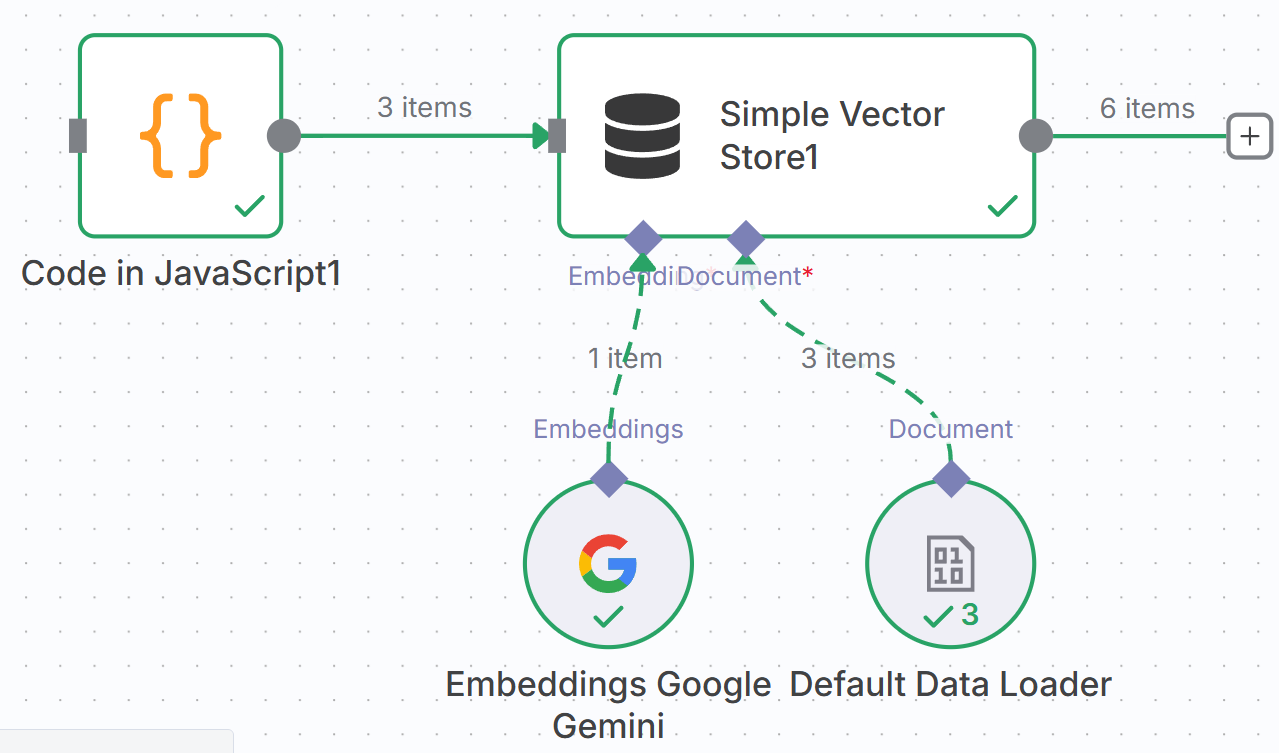
图 5.X 完整的知识库加载工作流
图 5.X 新建Gmail节点图
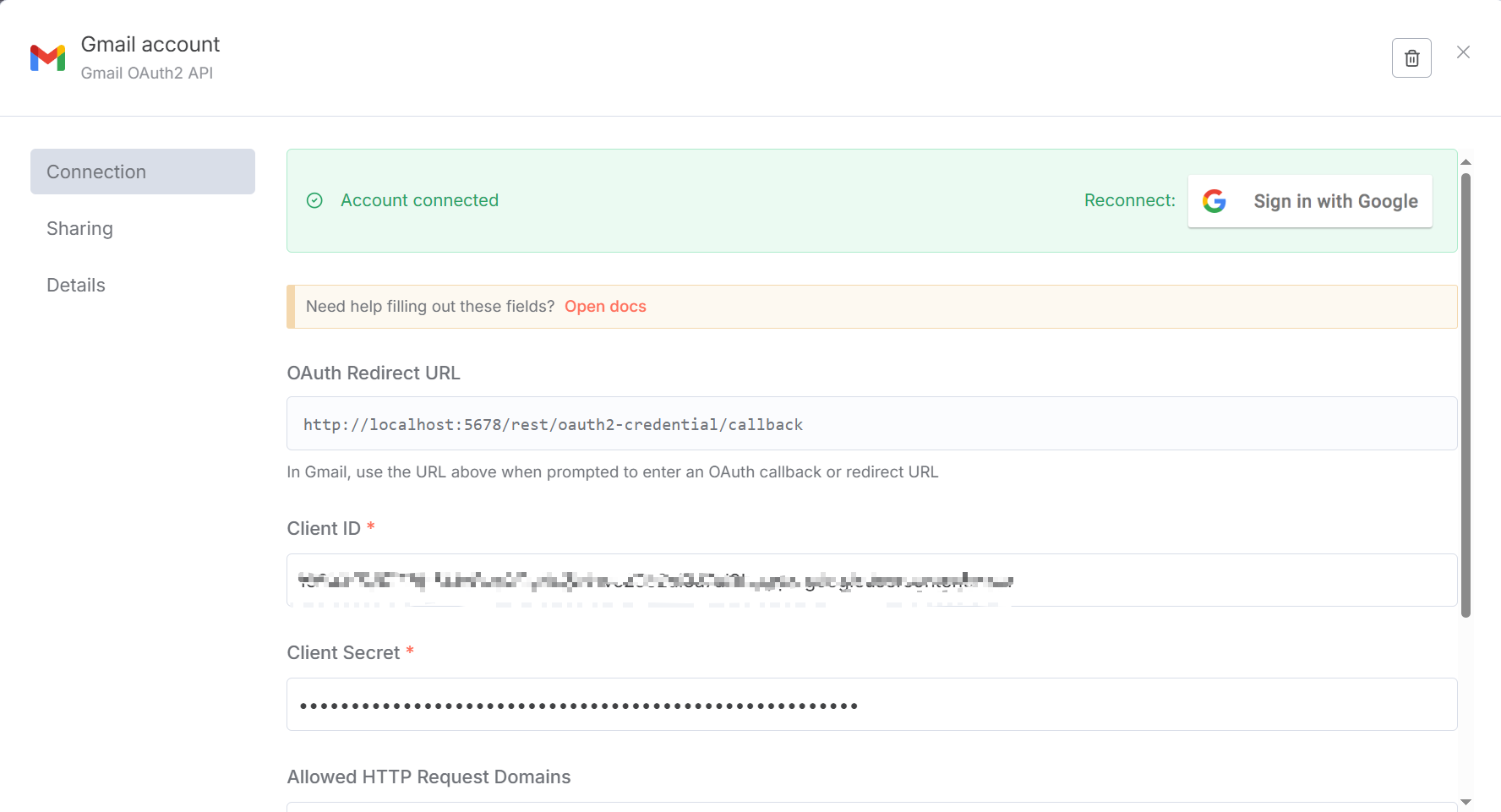
图 5.X Gmail账号加载成功图
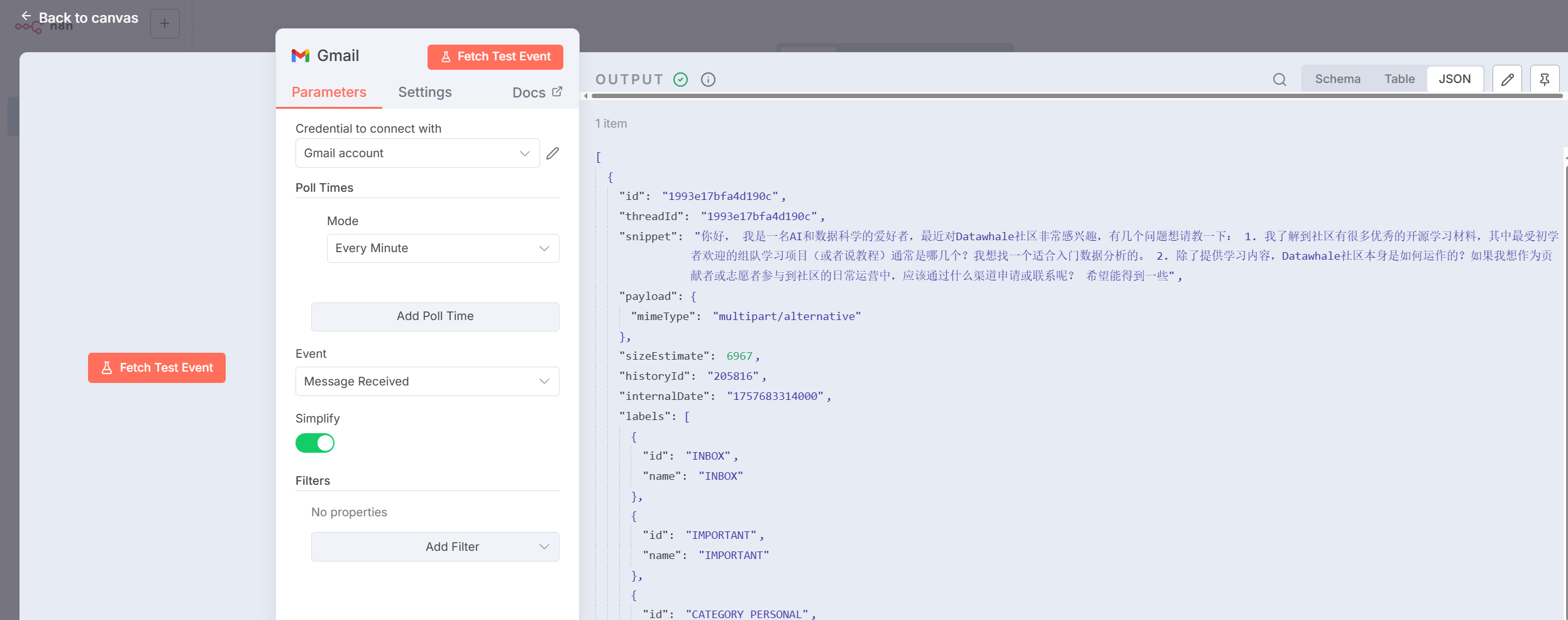
图 5.X 获取实时邮件图
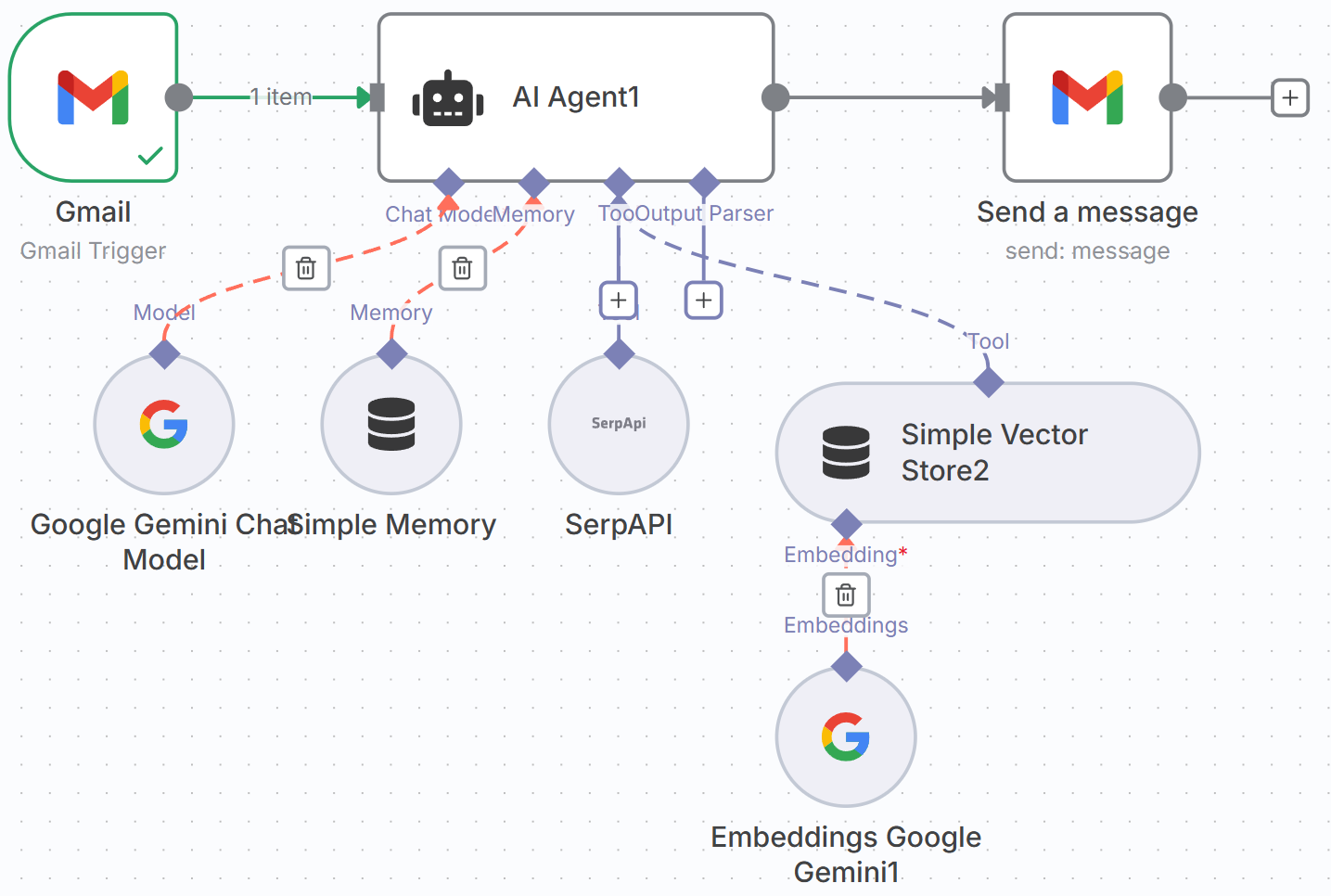
图 5.X AI Agent节点设置图
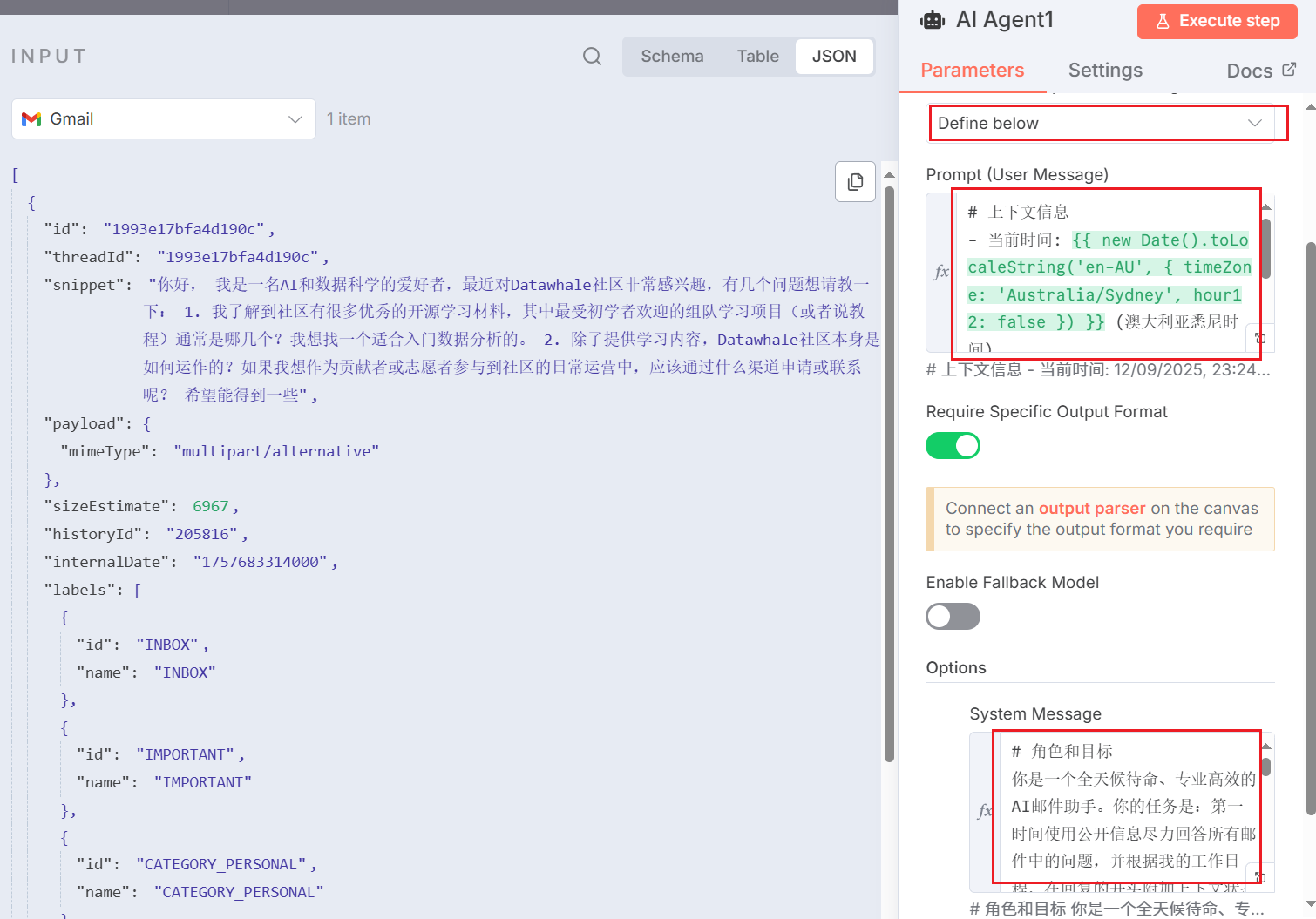
图 5.X AI Agent 节点详解图
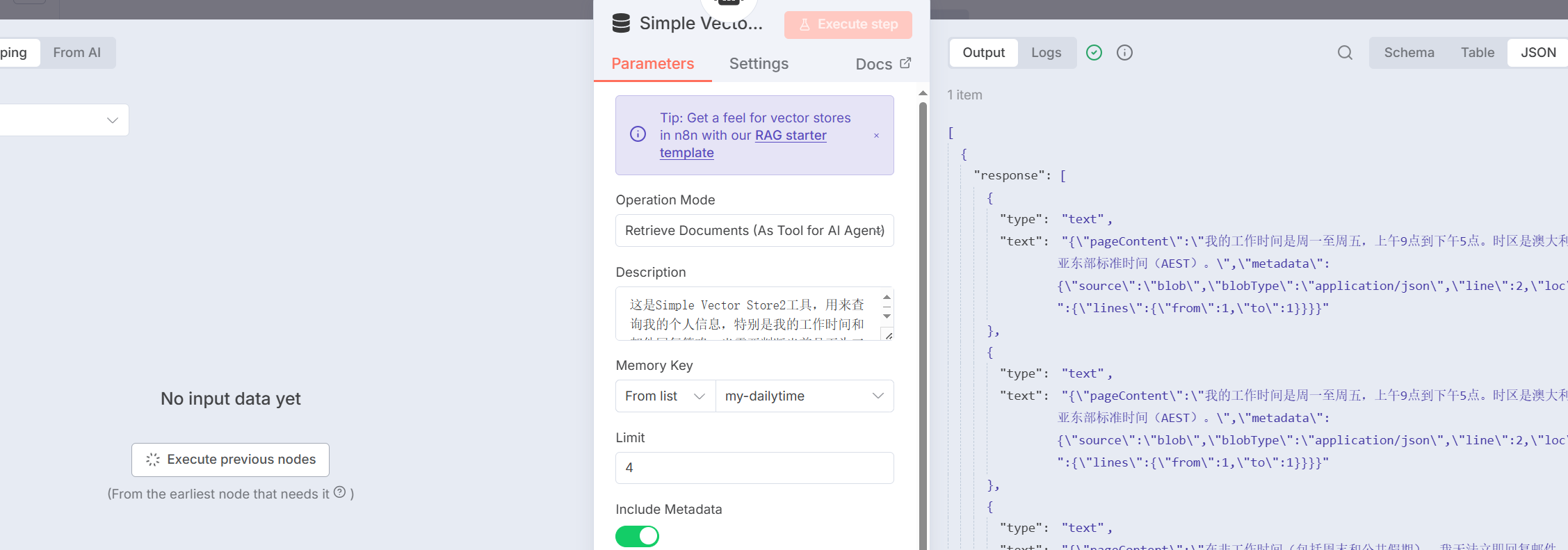
图 5.X Simple Vector Store工具配置
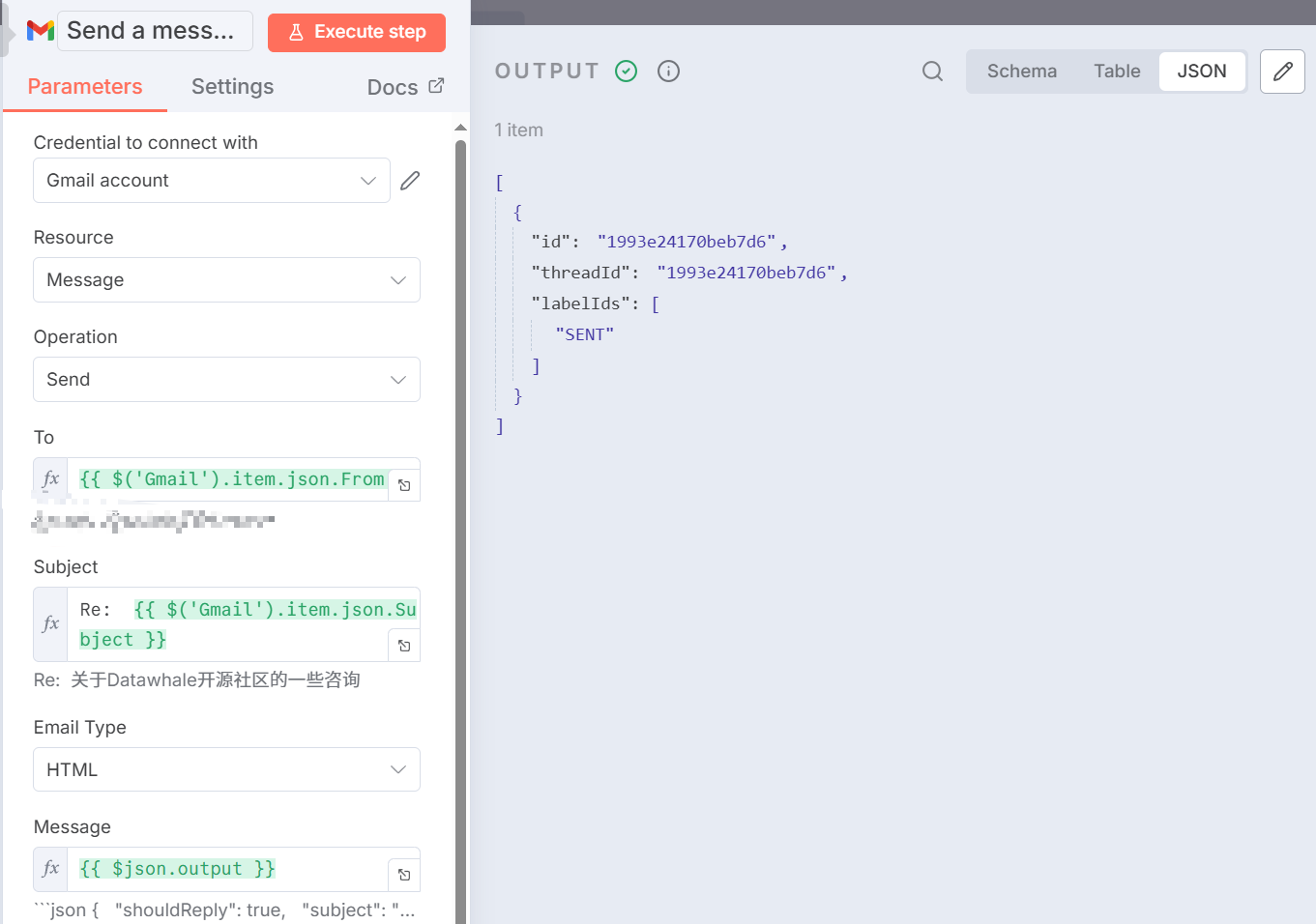
图 5.X 最终回复工具图示

图 5.X 个人邮箱返回邮件格式
表 5.X n8n 平台的优势与局限性总结
