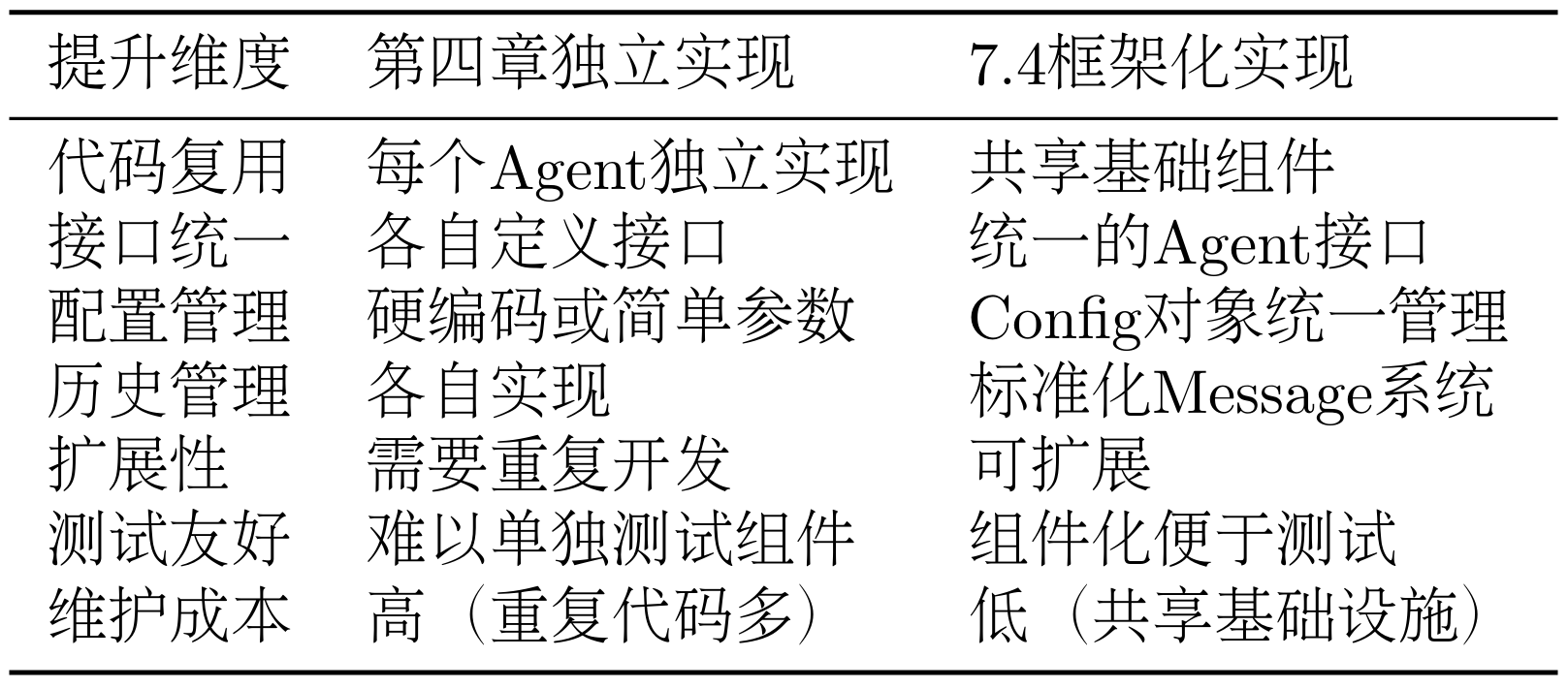
表 7.1 基于Helloagents的SimpleAgent运行工作流
### 7.5.3 多源搜索工具
在实际应用中,我们经常需要整合多个外部服务来提供更强大的功能。搜索工具就是一个典型的例子,它整合多个搜索引擎,能提供更加完备的真实信息。在第一章我们使用过Tavily的搜索API,在第四章我们使用过SerpApi的搜索API。因此这次我们使用这两个API来实现多源搜索功能。如果没安装对应的python依赖可以运行下面这条脚本:
```bash
pip install hello-agents[search]==0.1.1
```
(1)搜索工具的统一接口设计
HelloAgents框架内置的SearchTool展示了如何设计一个高级的多源搜索工具:
````python
class SearchTool(Tool):
"""
智能混合搜索工具
支持多种搜索引擎后端,智能选择最佳搜索源:
1. 混合模式 (hybrid) - 智能选择TAVILY或SERPAPI
2. Tavily API (tavily) - 专业AI搜索
3. SerpApi (serpapi) - 传统Google搜索
"""
def __init__(self, backend: str = "hybrid", tavily_key: Optional[str] = None, serpapi_key: Optional[str] = None):
super().__init__(
name="search",
description="一个智能网页搜索引擎。支持混合搜索模式,自动选择最佳搜索源。"
)
self.backend = backend
self.tavily_key = tavily_key or os.getenv("TAVILY_API_KEY")
self.serpapi_key = serpapi_key or os.getenv("SERPAPI_API_KEY")
self.available_backends = []
self._setup_backends()
````
这个设计的核心思想是根据可用的API密钥和依赖库,自动选择最佳的搜索后端。
(2)TAVILY与SERPAPI搜索源的整合策略
框架实现了智能的后端选择逻辑:
````python
def _search_hybrid(self, query: str) -> str:
"""混合搜索 - 智能选择最佳搜索源"""
# 优先使用Tavily(AI优化的搜索)
if "tavily" in self.available_backends:
try:
return self._search_tavily(query)
except Exception as e:
print(f"⚠️ Tavily搜索失败: {e}")
# 如果Tavily失败,尝试SerpApi
if "serpapi" in self.available_backends:
print("🔄 切换到SerpApi搜索")
return self._search_serpapi(query)
# 如果Tavily不可用,使用SerpApi
elif "serpapi" in self.available_backends:
try:
return self._search_serpapi(query)
except Exception as e:
print(f"⚠️ SerpApi搜索失败: {e}")
# 如果都不可用,提示用户配置API
return "❌ 没有可用的搜索源,请配置TAVILY_API_KEY或SERPAPI_API_KEY环境变量"
````
这种设计体现了高可用系统的核心理念:通过降级机制,系统能够从最优的搜索源逐步降级到可用的备选方案。当所有搜索源都不可用时,明确提示用户配置正确的API密钥。
(3)搜索结果的统一格式化
不同搜索引擎返回的结果格式不同,框架通过统一的格式化方法来处理:
````python
def _search_tavily(self, query: str) -> str:
"""使用Tavily搜索"""
response = self.tavily_client.search(
query=query,
search_depth="basic",
include_answer=True,
max_results=3
)
result = f"🎯 Tavily AI搜索结果:{response.get('answer', '未找到直接答案')}\n\n"
for i, item in enumerate(response.get('results', [])[:3], 1):
result += f"[{i}] {item.get('title', '')}\n"
result += f" {item.get('content', '')[:200]}...\n"
result += f" 来源: {item.get('url', '')}\n\n"
return result
````
基于框架的设计思想,我们可以创建自己的高级搜索工具。这次我们使用类的方式来展示不同的实现方法,创建`my_advanced_search.py`:
```python
# my_advanced_search.py
import os
from typing import Optional, List, Dict, Any
from hello_agents import ToolRegistry
class MyAdvancedSearchTool:
"""
自定义高级搜索工具类
展示多源整合和智能选择的设计模式
"""
def __init__(self):
self.name = "my_advanced_search"
self.description = "智能搜索工具,支持多个搜索源,自动选择最佳结果"
self.search_sources = []
self._setup_search_sources()
def _setup_search_sources(self):
"""设置可用的搜索源"""
# 检查Tavily可用性
if os.getenv("TAVILY_API_KEY"):
try:
from tavily import TavilyClient
self.tavily_client = TavilyClient(api_key=os.getenv("TAVILY_API_KEY"))
self.search_sources.append("tavily")
print("✅ Tavily搜索源已启用")
except ImportError:
print("⚠️ Tavily库未安装")
# 检查SerpApi可用性
if os.getenv("SERPAPI_API_KEY"):
try:
import serpapi
self.search_sources.append("serpapi")
print("✅ SerpApi搜索源已启用")
except ImportError:
print("⚠️ SerpApi库未安装")
if self.search_sources:
print(f"🔧 可用搜索源: {', '.join(self.search_sources)}")
else:
print("⚠️ 没有可用的搜索源,请配置API密钥")
def search(self, query: str) -> str:
"""执行智能搜索"""
if not query.strip():
return "❌ 错误:搜索查询不能为空"
# 检查是否有可用的搜索源
if not self.search_sources:
return """❌ 没有可用的搜索源,请配置以下API密钥之一:
1. Tavily API: 设置环境变量 TAVILY_API_KEY
获取地址: https://tavily.com/
2. SerpAPI: 设置环境变量 SERPAPI_API_KEY
获取地址: https://serpapi.com/
配置后重新运行程序。"""
print(f"🔍 开始智能搜索: {query}")
# 尝试多个搜索源,返回最佳结果
for source in self.search_sources:
try:
if source == "tavily":
result = self._search_with_tavily(query)
if result and "未找到" not in result:
return f"📊 Tavily AI搜索结果:\n\n{result}"
elif source == "serpapi":
result = self._search_with_serpapi(query)
if result and "未找到" not in result:
return f"🌐 SerpApi Google搜索结果:\n\n{result}"
except Exception as e:
print(f"⚠️ {source} 搜索失败: {e}")
continue
return "❌ 所有搜索源都失败了,请检查网络连接和API密钥配置"
def _search_with_tavily(self, query: str) -> str:
"""使用Tavily搜索"""
response = self.tavily_client.search(query=query, max_results=3)
if response.get('answer'):
result = f"💡 AI直接答案:{response['answer']}\n\n"
else:
result = ""
result += "🔗 相关结果:\n"
for i, item in enumerate(response.get('results', [])[:3], 1):
result += f"[{i}] {item.get('title', '')}\n"
result += f" {item.get('content', '')[:150]}...\n\n"
return result
def _search_with_serpapi(self, query: str) -> str:
"""使用SerpApi搜索"""
import serpapi
search = serpapi.GoogleSearch({
"q": query,
"api_key": os.getenv("SERPAPI_API_KEY"),
"num": 3
})
results = search.get_dict()
result = "🔗 Google搜索结果:\n"
if "organic_results" in results:
for i, res in enumerate(results["organic_results"][:3], 1):
result += f"[{i}] {res.get('title', '')}\n"
result += f" {res.get('snippet', '')}\n\n"
return result
def create_advanced_search_registry():
"""创建包含高级搜索工具的注册表"""
registry = ToolRegistry()
# 创建搜索工具实例
search_tool = MyAdvancedSearchTool()
# 注册搜索工具的方法作为函数
registry.register_function(
name="advanced_search",
description="高级搜索工具,整合Tavily和SerpAPI多个搜索源,提供更全面的搜索结果",
func=search_tool.search
)
return registry
```
接下来可以测试我们自己编写的工具,创建`test_advanced_search.py`:
```python
# test_advanced_search.py
from dotenv import load_dotenv
from my_advanced_search import create_advanced_search_registry, MyAdvancedSearchTool
# 加载环境变量
load_dotenv()
def test_advanced_search():
"""测试高级搜索工具"""
# 创建包含高级搜索工具的注册表
registry = create_advanced_search_registry()
print("🔍 测试高级搜索工具\n")
# 测试查询
test_queries = [
"Python编程语言的历史",
"人工智能的最新发展",
"2024年科技趋势"
]
for i, query in enumerate(test_queries, 1):
print(f"测试 {i}: {query}")
result = registry.execute_tool("advanced_search", query)
print(f"结果: {result}\n")
print("-" * 60 + "\n")
def test_api_configuration():
"""测试API配置检查"""
print("🔧 测试API配置检查:")
# 直接创建搜索工具实例
search_tool = MyAdvancedSearchTool()
# 如果没有配置API,会显示配置提示
result = search_tool.search("机器学习算法")
print(f"搜索结果: {result}")
def test_with_agent():
"""测试与Agent的集成"""
print("\n🤖 与Agent集成测试:")
print("高级搜索工具已准备就绪,可以与Agent集成使用")
# 显示工具描述
registry = create_advanced_search_registry()
tools_desc = registry.get_tools_description()
print(f"工具描述:\n{tools_desc}")
if __name__ == "__main__":
test_advanced_search()
test_api_configuration()
test_with_agent()
```
通过这个高级搜索工具的设计实践,我们学会了如何使用类的方式来构建复杂的工具系统。相比函数方式,类方式更适合需要维护状态(如API客户端、配置信息)的工具。
### 7.5.4 工具系统的高级特性
在掌握了基础的工具开发和多源整合后,我们来探讨工具系统的高级特性。这些特性能够让工具系统在复杂的生产环境中稳定运行,并为Agent提供更强大的能力。
(1)工具链式调用机制
在实际应用中,Agent经常需要组合使用多个工具来完成复杂任务。我们可以设计一个工具链管理器来支持这种场景,这里借鉴了第六章中提到的图的概念:
```python
# tool_chain_manager.py
from typing import List, Dict, Any, Optional
from hello_agents import ToolRegistry
class ToolChain:
"""工具链 - 支持多个工具的顺序执行"""
def __init__(self, name: str, description: str):
self.name = name
self.description = description
self.steps: List[Dict[str, Any]] = []
def add_step(self, tool_name: str, input_template: str, output_key: str = None):
"""
添加工具执行步骤
Args:
tool_name: 工具名称
input_template: 输入模板,支持变量替换
output_key: 输出结果的键名,用于后续步骤引用
"""
self.steps.append({
"tool_name": tool_name,
"input_template": input_template,
"output_key": output_key or f"step_{len(self.steps)}_result"
})
def execute(self, registry: ToolRegistry, initial_input: str, context: Dict[str, Any] = None) -> str:
"""执行工具链"""
context = context or {}
context["input"] = initial_input
print(f"🔗 开始执行工具链: {self.name}")
for i, step in enumerate(self.steps, 1):
tool_name = step["tool_name"]
input_template = step["input_template"]
output_key = step["output_key"]
# 替换模板中的变量
try:
tool_input = input_template.format(**context)
except KeyError as e:
return f"❌ 工具链执行失败:模板变量 {e} 未找到"
print(f" 步骤 {i}: 使用 {tool_name} 处理 '{tool_input[:50]}...'")
# 执行工具
result = registry.execute_tool(tool_name, tool_input)
context[output_key] = result
print(f" ✅ 步骤 {i} 完成,结果长度: {len(result)} 字符")
# 返回最后一步的结果
final_result = context[self.steps[-1]["output_key"]]
print(f"🎉 工具链 '{self.name}' 执行完成")
return final_result
class ToolChainManager:
"""工具链管理器"""
def __init__(self, registry: ToolRegistry):
self.registry = registry
self.chains: Dict[str, ToolChain] = {}
def register_chain(self, chain: ToolChain):
"""注册工具链"""
self.chains[chain.name] = chain
print(f"✅ 工具链 '{chain.name}' 已注册")
def execute_chain(self, chain_name: str, input_data: str, context: Dict[str, Any] = None) -> str:
"""执行指定的工具链"""
if chain_name not in self.chains:
return f"❌ 工具链 '{chain_name}' 不存在"
chain = self.chains[chain_name]
return chain.execute(self.registry, input_data, context)
def list_chains(self) -> List[str]:
"""列出所有工具链"""
return list(self.chains.keys())
# 使用示例
def create_research_chain() -> ToolChain:
"""创建一个研究工具链:搜索 -> 计算 -> 总结"""
chain = ToolChain(
name="research_and_calculate",
description="搜索信息并进行相关计算"
)
# 步骤1:搜索信息
chain.add_step(
tool_name="search",
input_template="{input}",
output_key="search_result"
)
# 步骤2:基于搜索结果进行计算(如果需要)
chain.add_step(
tool_name="my_calculator",
input_template="根据以下信息计算相关数值:{search_result}",
output_key="calculation_result"
)
return chain
```
(2)异步工具执行支持
对于耗时的工具操作,我们可以提供异步执行支持:
```python
# async_tool_executor.py
import asyncio
import concurrent.futures
from typing import Dict, Any, List, Callable
from hello_agents import ToolRegistry
class AsyncToolExecutor:
"""异步工具执行器"""
def __init__(self, registry: ToolRegistry, max_workers: int = 4):
self.registry = registry
self.executor = concurrent.futures.ThreadPoolExecutor(max_workers=max_workers)
async def execute_tool_async(self, tool_name: str, input_data: str) -> str:
"""异步执行单个工具"""
loop = asyncio.get_event_loop()
def _execute():
return self.registry.execute_tool(tool_name, input_data)
result = await loop.run_in_executor(self.executor, _execute)
return result
async def execute_tools_parallel(self, tasks: List[Dict[str, str]]) -> List[str]:
"""并行执行多个工具"""
print(f"🚀 开始并行执行 {len(tasks)} 个工具任务")
# 创建异步任务
async_tasks = []
for task in tasks:
tool_name = task["tool_name"]
input_data = task["input_data"]
async_task = self.execute_tool_async(tool_name, input_data)
async_tasks.append(async_task)
# 等待所有任务完成
results = await asyncio.gather(*async_tasks)
print(f"✅ 所有工具任务执行完成")
return results
def __del__(self):
"""清理资源"""
if hasattr(self, 'executor'):
self.executor.shutdown(wait=True)
# 使用示例
async def test_parallel_execution():
"""测试并行工具执行"""
from hello_agents import ToolRegistry
registry = ToolRegistry()
# 假设已经注册了搜索和计算工具
executor = AsyncToolExecutor(registry)
# 定义并行任务
tasks = [
{"tool_name": "search", "input_data": "Python编程"},
{"tool_name": "search", "input_data": "机器学习"},
{"tool_name": "my_calculator", "input_data": "2 + 2"},
{"tool_name": "my_calculator", "input_data": "sqrt(16)"},
]
# 并行执行
results = await executor.execute_tools_parallel(tasks)
for i, result in enumerate(results):
print(f"任务 {i+1} 结果: {result[:100]}...")
```
基于以上的设计和实现经验,我们可以总结出工具系统开发的核心理念:在设计层面,每个工具都应该遵循单一职责原则,专注于特定功能的同时保持接口的统一性,并将完善的异常处理和安全优先的输入验证作为基本要求。在性能优化方面,利用异步执行提高并发处理能力,同时合理管理外部连接和系统资源。
## 7.6 本章小结
在正式总结之前,我们想告诉大家一个好消息:对于本章实现的所有方法和功能,都在GitHub仓库中提供了完整的测试案例。你可以访问[这个链接](https://github.com/jjyaoao/HelloAgents/blob/main/examples/chapter07_basic_setup.py)查看和运行这些测试代码。这个文件包含了四种Agent范式的演示、工具系统的集成测试、高级功能的使用示例,以及交互式的Agent体验。如果你想验证自己的实现是否正确,或者想深入了解框架的实际使用方式,这些测试案例将是有价值的参考。
回顾本章,我们完成了一项富有挑战的任务:一步步构建了一个基础的智能体框架——HelloAgents。这个过程始终遵循着“分层解耦、职责单一、接口统一”的核心原则。
在框架的具体实现中,我们再次实现了四种经典的Agent范式。从SimpleAgent的基础对话模式,到ReActAgent的推理与行动结合;从ReflectionAgent的自我反思与迭代优化,到PlanAndSolveAgent的分解规划与逐步执行。而工具系统作为Agent能力延伸的核心,其构建过程则是一次完整的工程实践。
更重要的是,第七章的构建并非终点,而是为后续更深入学习提供了必要的技术基础。我们在设计之初便充分考虑了后续内容的延展性,为高级功能的实现预留了必要的接口和扩展点。我们所建立的统一LLM接口、标准化消息系统、工具注册机制,共同构成了一个完备的技术底座。这使得我们在后续章节中,可以更加从容地去学习更高级的主题:第八章的记忆与RAG系统将基于此扩展Agent的能力边界;第九章的上下文工程将深入我们已经建立的消息处理机制;第十章的智能体协议则需要扩展新的工具。
接下来,我们将一起探索如何往框架中加入RAG系统与Memory机制,敬请期待第八章!