# 第八章 记忆与检索
在前面的章节中,我们构建了HelloAgents框架的基础架构,实现了多种智能体范式和工具系统。不过,我们的框架还缺少一个关键能力:记忆。如果智能体无法记住之前的交互内容,也无法从历史经验中学习,那么在连续对话或复杂任务中,其表现将受到极大限制。
本章将在第七章构建的框架基础上,为HelloAgents增加两个核心能力:记忆系统(Memory System)和检索增强生成(Retrieval-Augmented Generation, RAG)。我们将采用"框架扩展 + 知识科普"的方式,在构建过程中深入理解Memory和RAG的理论基础,最终实现一个具有完整记忆和知识检索能力的智能体系统。
## 8.1 从认知科学到智能体记忆
### 8.1.1 人类记忆系统的启发
在构建智能体的记忆系统之前,让我们先从认知科学的角度理解人类是如何处理和存储信息的。人类记忆是一个多层级的认知系统,它不仅能存储信息,还能根据重要性、时间和上下文对信息进行分类和整理。认知心理学为理解记忆的结构和过程提供了经典的理论框架[1],如图8.1所示。
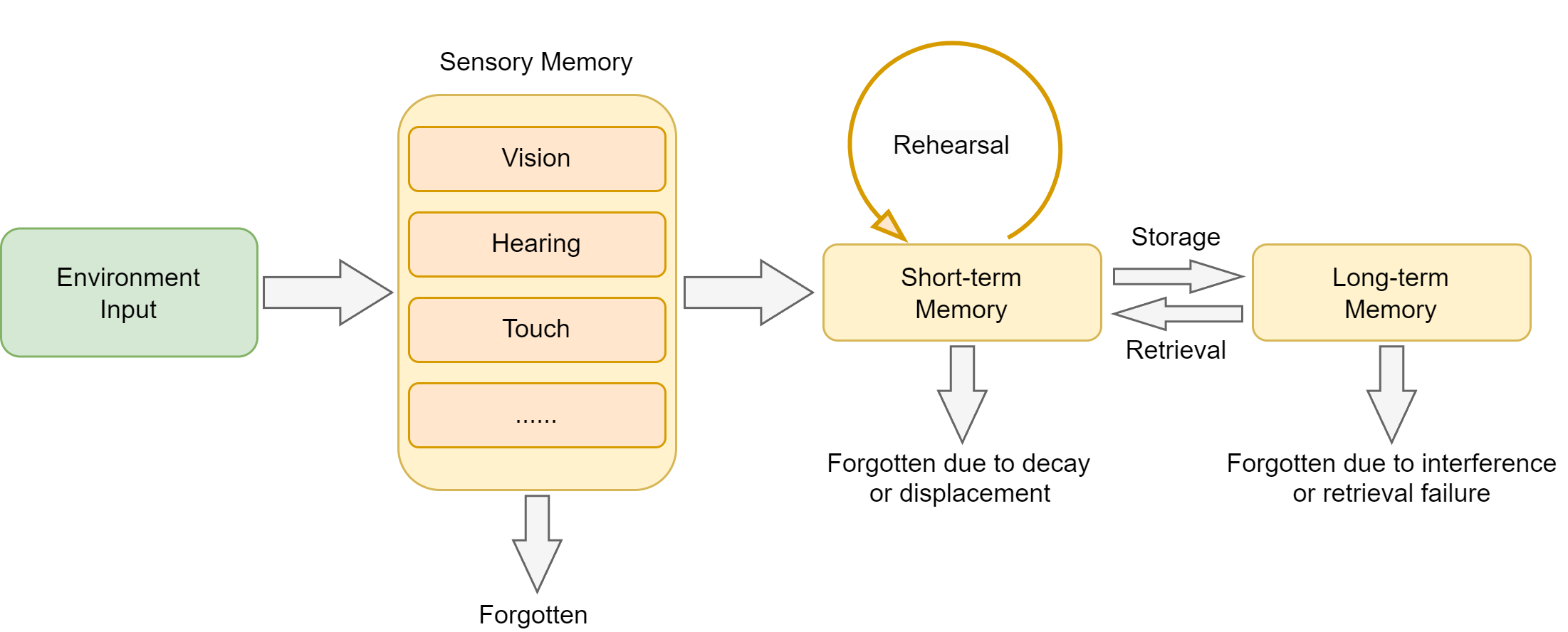
图 8.1 人类记忆系统的层次结构
根据认知心理学的研究,人类记忆可以分为以下几个层次:
1. 感觉记忆(Sensory Memory):持续时间极短(0.5-3秒),容量巨大,负责暂时保存感官接收到的所有信息
2. 工作记忆(Working Memory):持续时间短(15-30秒),容量有限(7±2个项目),负责当前任务的信息处理
3. 长期记忆(Long-term Memory):持续时间长(可达终生),容量几乎无限,进一步分为:
- 程序性记忆:技能和习惯(如骑自行车)
- 陈述性记忆:可以用语言表达的知识,又分为:
- 语义记忆:一般知识和概念(如"巴黎是法国首都")
- 情景记忆:个人经历和事件(如"昨天的会议内容")
### 8.1.2 为何智能体需要记忆与RAG
借鉴人类记忆系统的设计,我们可以理解为什么智能体也需要类似的记忆能力。人类智能的一个重要特征就是能够记住过去的经历,从中学习,并将这些经验应用到新的情况中。同样,一个真正智能的智能体也需要具备记忆能力。对于基于LLM的智能体而言,通常面临两个根本性局限:对话状态的遗忘和内置知识的局限。
(1)局限一:无状态导致的对话遗忘
当前的大语言模型虽然强大,但设计上是无状态的。这意味着,每一次用户请求(或API调用)都是一次独立的、无关联的计算。模型本身不会自动“记住”上一次对话的内容。这带来了几个问题:
1. 上下文丢失:在长对话中,早期的重要信息可能会因为上下文窗口限制而丢失
2. 个性化缺失:Agent无法记住用户的偏好、习惯或特定需求
3. 学习能力受限:无法从过往的成功或失败经验中学习改进
4. 一致性问题:在多轮对话中可能出现前后矛盾的回答
让我们通过一个具体例子来理解这个问题:
```python
# 第七章的Agent使用方式
from hello_agents import SimpleAgent, HelloAgentsLLM
agent = SimpleAgent(name="学习助手", llm=HelloAgentsLLM())
# 第一次对话
response1 = agent.run("我叫张三,正在学习Python,目前掌握了基础语法")
print(response1) # "很好!Python基础语法是编程的重要基础..."
# 第二次对话(新的会话)
response2 = agent.run("你还记得我的学习进度吗?")
print(response2) # "抱歉,我不知道您的学习进度..."
```
要解决这个问题,我们的框架需要引入记忆系统。
(2)局限二:模型内置知识的局限性
除了遗忘对话历史,LLM 的另一个核心局限在于其知识是静态的、有限的。这些知识完全来自于它的训练数据,并因此带来一系列问题:
1. 知识时效性:大模型的训练数据有时间截止点,无法获取最新信息
2. 专业领域知识:通用模型在特定领域的深度知识可能不足
3. 事实准确性:通过检索验证,减少模型的幻觉问题
4. 可解释性:提供信息来源,增强回答的可信度
为了克服这一局限,RAG技术应运而生。它的核心思想是在模型生成回答之前,先从一个外部知识库(如文档、数据库、API)中检索出最相关的信息,并将这些信息作为上下文一同提供给模型。
### 8.1.3 记忆与RAG系统架构设计
基于第七章建立的框架基础和认知科学的启发,我们设计了一个分层的记忆与RAG系统架构,如图8.2所示。这个架构不仅借鉴了人类记忆系统的层次结构,还充分考虑了工程实现的可扩展性。在实现上,我们将记忆和RAG设计为两个独立的工具:`memory_tool`负责存储和维护对话过程中的交互信息,`rag_tool`则负责从用户提供的知识库中检索相关信息作为上下文,并可将重要的检索结果自动存储到记忆系统中。
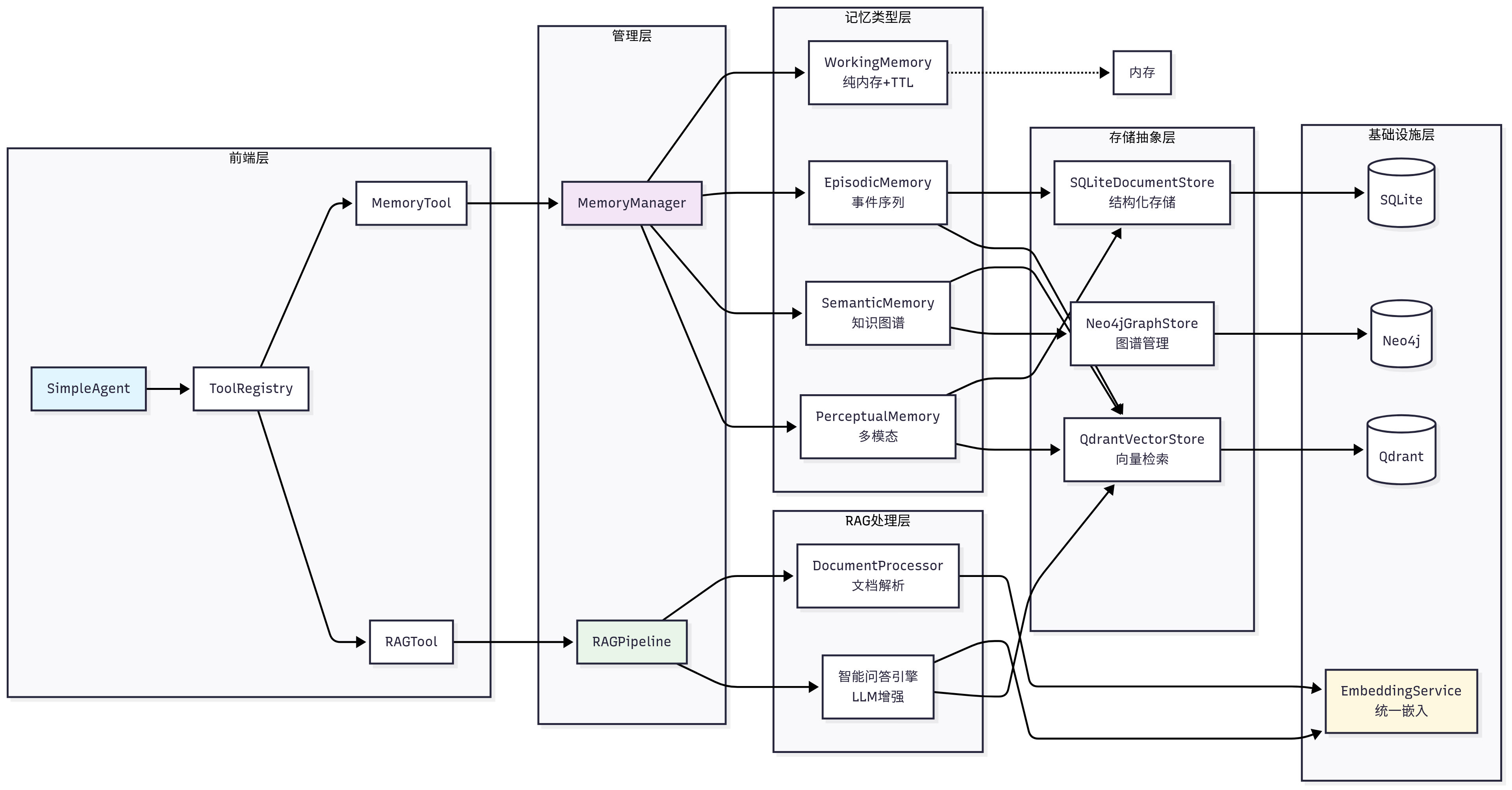
图 8.2 HelloAgents记忆与RAG系统整体架构
记忆系统采用了四层架构设计:
```
HelloAgents记忆系统
├── 基础设施层 (Infrastructure Layer)
│ ├── MemoryManager - 记忆管理器(统一调度和协调)
│ ├── MemoryItem - 记忆数据结构(标准化记忆项)
│ ├── MemoryConfig - 配置管理(系统参数设置)
│ └── BaseMemory - 记忆基类(通用接口定义)
├── 记忆类型层 (Memory Types Layer)
│ ├── WorkingMemory - 工作记忆(临时信息,TTL管理)
│ ├── EpisodicMemory - 情景记忆(具体事件,时间序列)
│ ├── SemanticMemory - 语义记忆(抽象知识,图谱关系)
│ └── PerceptualMemory - 感知记忆(多模态数据)
├── 存储后端层 (Storage Backend Layer)
│ ├── QdrantVectorStore - 向量存储(高性能语义检索)
│ ├── Neo4jGraphStore - 图存储(知识图谱管理)
│ └── SQLiteDocumentStore - 文档存储(结构化持久化)
└── 嵌入服务层 (Embedding Service Layer)
├── DashScopeEmbedding - 通义千问嵌入(云端API)
├── LocalTransformerEmbedding - 本地嵌入(离线部署)
└── TFIDFEmbedding - TFIDF嵌入(轻量级兜底)
```
RAG系统专注于外部知识的获取和利用:
```
HelloAgents RAG系统
├── 文档处理层 (Document Processing Layer)
│ ├── DocumentProcessor - 文档处理器(多格式解析)
│ ├── Document - 文档对象(元数据管理)
│ └── Pipeline - RAG管道(端到端处理)
├── 嵌入表示层 (Embedding Layer)
│ └── 统一嵌入接口 - 复用记忆系统的嵌入服务
├── 向量存储层 (Vector Storage Layer)
│ └── QdrantVectorStore - 向量数据库(命名空间隔离)
└── 智能问答层 (Intelligent Q&A Layer)
├── 多策略检索 - 向量检索 + MQE + HyDE
├── 上下文构建 - 智能片段合并与截断
└── LLM增强生成 - 基于上下文的准确问答
```
### 8.1.4 本章学习目标与快速体验
让我们先看看第八章的核心学习内容:
```
hello-agents/
├── hello_agents/
│ ├── memory/ # 记忆系统模块
│ │ ├── base.py # 基础数据结构(MemoryItem, MemoryConfig, BaseMemory)
│ │ ├── manager.py # 记忆管理器(统一协调调度)
│ │ ├── embedding.py # 统一嵌入服务(DashScope/Local/TFIDF)
│ │ ├── types/ # 记忆类型实现
│ │ │ ├── working.py # 工作记忆(TTL管理,纯内存)
│ │ │ ├── episodic.py # 情景记忆(事件序列,SQLite+Qdrant)
│ │ │ ├── semantic.py # 语义记忆(知识图谱,Qdrant+Neo4j)
│ │ │ └── perceptual.py # 感知记忆(多模态,SQLite+Qdrant)
│ │ ├── storage/ # 存储后端实现
│ │ │ ├── qdrant_store.py # Qdrant向量存储(高性能向量检索)
│ │ │ ├── neo4j_store.py # Neo4j图存储(知识图谱管理)
│ │ │ └── document_store.py # SQLite文档存储(结构化持久化)
│ │ └── rag/ # RAG系统
│ │ ├── pipeline.py # RAG管道(端到端处理)
│ │ └── document.py # 文档处理器(多格式解析)
│ └── tools/builtin/ # 扩展内置工具
│ ├── memory_tool.py # 记忆工具(Agent记忆能力)
│ └── rag_tool.py # RAG工具(智能问答能力)
└──
```
快速开始:安装HelloAgents框架
为了让读者能够快速体验本章的完整功能,我们提供了可直接安装的Python包。你可以通过以下命令安装本章对应的版本:
```bash
pip install hello-agents[all]==0.2.0
```
除了这一个指令外,还需要在`.env`配置图数据库,向量数据库,LLM以及Embedding方案的API。在教程中向量数据库采用Qdrant,图数据库采用Neo4J,Embedding首选百炼平台,若没有API可切换为本地部署模型方案。
```bash
# ================================
# Qdrant 向量数据库配置 - 获取API密钥:https://cloud.qdrant.io/
# ================================
# 使用Qdrant云服务 (推荐)
QDRANT_URL=https://your-cluster.qdrant.tech:6333
QDRANT_API_KEY=your_qdrant_api_key_here
# 或使用本地Qdrant (需要Docker)
# QDRANT_URL=http://localhost:6333
# QDRANT_API_KEY=
# Qdrant集合配置
QDRANT_COLLECTION=hello_agents_vectors
QDRANT_VECTOR_SIZE=384
QDRANT_DISTANCE=cosine
QDRANT_TIMEOUT=30
# ================================
# Neo4j 图数据库配置 - 获取API密钥:https://neo4j.com/cloud/aura/
# ================================
# 使用Neo4j Aura云服务 (推荐)
NEO4J_URI=neo4j+s://your-instance.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=your_neo4j_password_here
# 或使用本地Neo4j (需要Docker)
# NEO4J_URI=bolt://localhost:7687
# NEO4J_USERNAME=neo4j
# NEO4J_PASSWORD=hello-agents-password
# Neo4j连接配置
NEO4J_DATABASE=neo4j
NEO4J_MAX_CONNECTION_LIFETIME=3600
NEO4J_MAX_CONNECTION_POOL_SIZE=50
NEO4J_CONNECTION_TIMEOUT=60
# ==========================
# 嵌入(Embedding)配置示例 - 可从阿里云控制台获取:https://dashscope.aliyun.com/
# ==========================
# - 若为空,dashscope 默认 text-embedding-v3;local 默认 sentence-transformers/all-MiniLM-L6-v2
EMBED_MODEL_TYPE=dashscope
EMBED_MODEL_NAME=
EMBED_API_KEY=
EMBED_BASE_URL=
```
本章的学习可以采用两种方式:
1. 体验式学习:直接使用`pip`安装框架,运行示例代码,快速体验各种功能
2. 深度学习:跟随本章内容,从零开始实现每个组件,深入理解框架的设计思想和实现细节
我们建议采用"先体验,后实现"的学习路径。在本章中,我们提供了完整的测试文件,你可以重写核心函数并运行测试,以检验你的实现是否正确。
遵循第七章确立的设计原则,我们将记忆和RAG能力封装为标准工具,而不是创建新的Agent类。在开始之前,让我们用30秒体验使用Hello-agents构建具有记忆和RAG能力的智能体!
```python
# 配置好同级文件夹下.env中的大模型API
from hello_agents import SimpleAgent, HelloAgentsLLM, ToolRegistry
from hello_agents.tools import MemoryTool, RAGTool
# 创建LLM实例
llm = HelloAgentsLLM()
# 创建Agent
agent = SimpleAgent(
name="智能助手",
llm=llm,
system_prompt="你是一个有记忆和知识检索能力的AI助手"
)
# 创建工具注册表
tool_registry = ToolRegistry()
# 添加记忆工具
memory_tool = MemoryTool(user_id="user123")
tool_registry.register_tool(memory_tool)
# 添加RAG工具
rag_tool = RAGTool(knowledge_base_path="./knowledge_base")
tool_registry.register_tool(rag_tool)
# 为Agent配置工具
agent.tool_registry = tool_registry
# 开始对话
response = agent.run("你好!请记住我叫张三,我是一名Python开发者")
print(response)
```
如果一切配置完毕,可以看到以下内容。
```bash
[OK] SQLite 数据库表和索引创建完成
[OK] SQLite 文档存储初始化完成: ./memory_data\memory.db
INFO:hello_agents.memory.storage.qdrant_store:✅ 成功连接到Qdrant云服务: https://0c517275-2ad0-4442-8309-11c36dc7e811.us-east-1-1.aws.cloud.qdrant.io:6333
INFO:hello_agents.memory.storage.qdrant_store:✅ 使用现有Qdrant集合: hello_agents_vectors
INFO:hello_agents.memory.types.semantic:✅ 嵌入模型就绪,维度: 1024
INFO:hello_agents.memory.types.semantic:✅ Qdrant向量数据库初始化完成
INFO:hello_agents.memory.storage.neo4j_store:✅ 成功连接到Neo4j云服务: neo4j+s://851b3a28.databases.neo4j.io NFO:hello_agents.memory.types.semantic:✅ Neo4j图数据库初始化完成
INFO:hello_agents.memory.storage.neo4j_store:✅ Neo4j索引创建完成
INFO:hello_agents.memory.types.semantic:✅ Neo4j图数据库初始化完成
INFO:hello_agents.memory.types.semantic:🏥 数据库健康状态: Qdrant=✅, Neo4j=✅
INFO:hello_agents.memory.types.semantic:✅ 加载中文spaCy模型: zh_core_web_sm
INFO:hello_agents.memory.types.semantic:✅ 加载英文spaCy模型: en_core_web_sm
INFO:hello_agents.memory.types.semantic:📚 可用语言模型: 中文, 英文
INFO:hello_agents.memory.types.semantic:增强语义记忆初始化完成(使用Qdrant+Neo4j专业数据库)
INFO:hello_agents.memory.manager:MemoryManager初始化完成,启用记忆类型: ['working', 'episodic', 'semantic']
✅ 工具 'memory' 已注册。
INFO:hello_agents.memory.storage.qdrant_store:✅ 成功连接到Qdrant云服务: https://0c517275-2ad0-4442-8309-11c36dc7eNFO:hello_agents.memory.storage.qdrant_store:✅ 使用现有Qdrant集合: rag_knowledge_base
811.us-east-1-1.aws.cloud.qdrant.io:6333
INFO:hello_agents.memory.storage.qdrant_store:✅ 使用现有Qdrant集合: rag_knowledge_base
✅ RAG工具初始化成功: namespace=default, collection=rag_knowledge_base
✅ 工具 'rag' 已注册。
你好,张三!很高兴认识你。作为一名Python开发者,你一定对编程很有热情。如果你有任何技术问题或者需要讨论Python相关
的话题,随时可以找我。我会尽力帮助你。有什么我现在就能帮到你的吗?
```
## 8.2 记忆系统:让智能体拥有记忆
### 8.2.1 记忆系统的工作流程
在进入代码实现阶段前,我们需要先定义记忆系统的工作流程。该流程参考了认知科学中的记忆模型,并将每个认知阶段映射为具体的技术组件和操作。理解这一映射关系,有助于我们后续的代码实现。
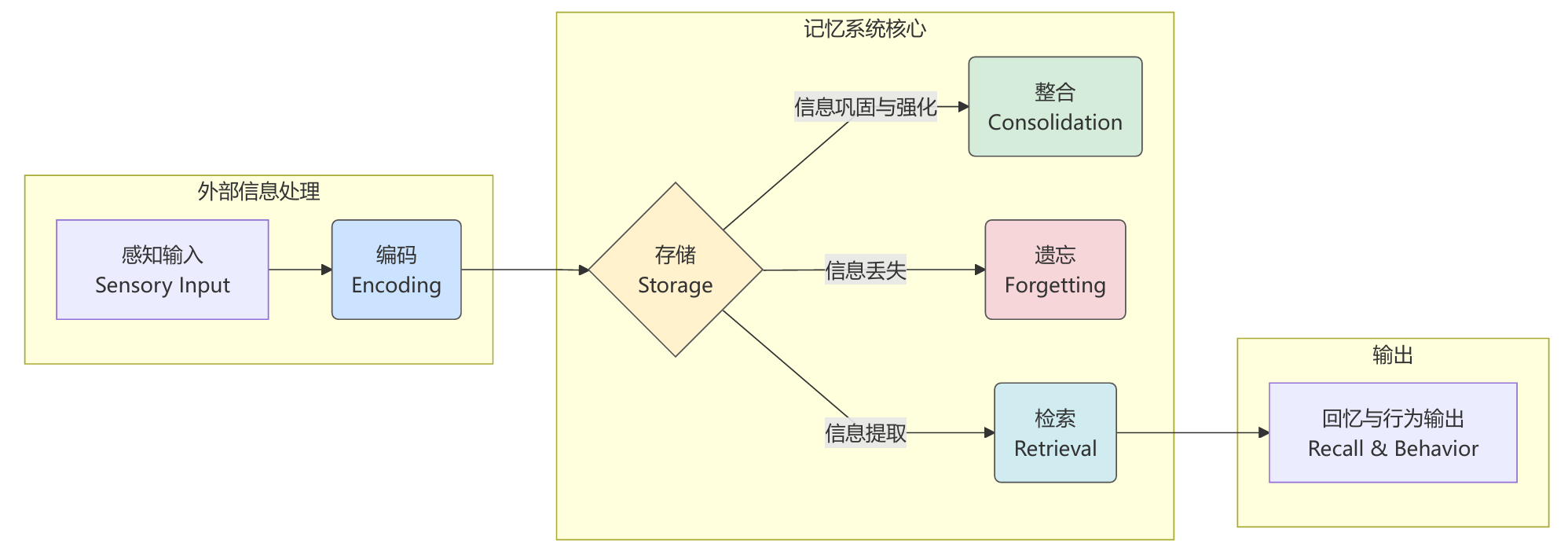
图 8.3 记忆形成的认知过程
如图8.3所示,根据认知科学的研究,人类记忆的形成经历以下几个阶段:
1. 编码(Encoding):将感知到的信息转换为可存储的形式
2. 存储(Storage):将编码后的信息保存在记忆系统中
3. 检索(Retrieval):根据需要从记忆中提取相关信息
4. 整合(Consolidation):将短期记忆转化为长期记忆
5. 遗忘(Forgetting):删除不重要或过时的信息
基于该启发,我们为 HelloAgents 设计了一套完整的记忆系统。其核心思想是模仿人类大脑处理不同类型信息的方式,将记忆划分为多个专门的模块,并建立一套智能化的管理机制。图8.4详细展示了这套系统的工作流程,包括记忆的添加、检索、整合和遗忘等关键环节。
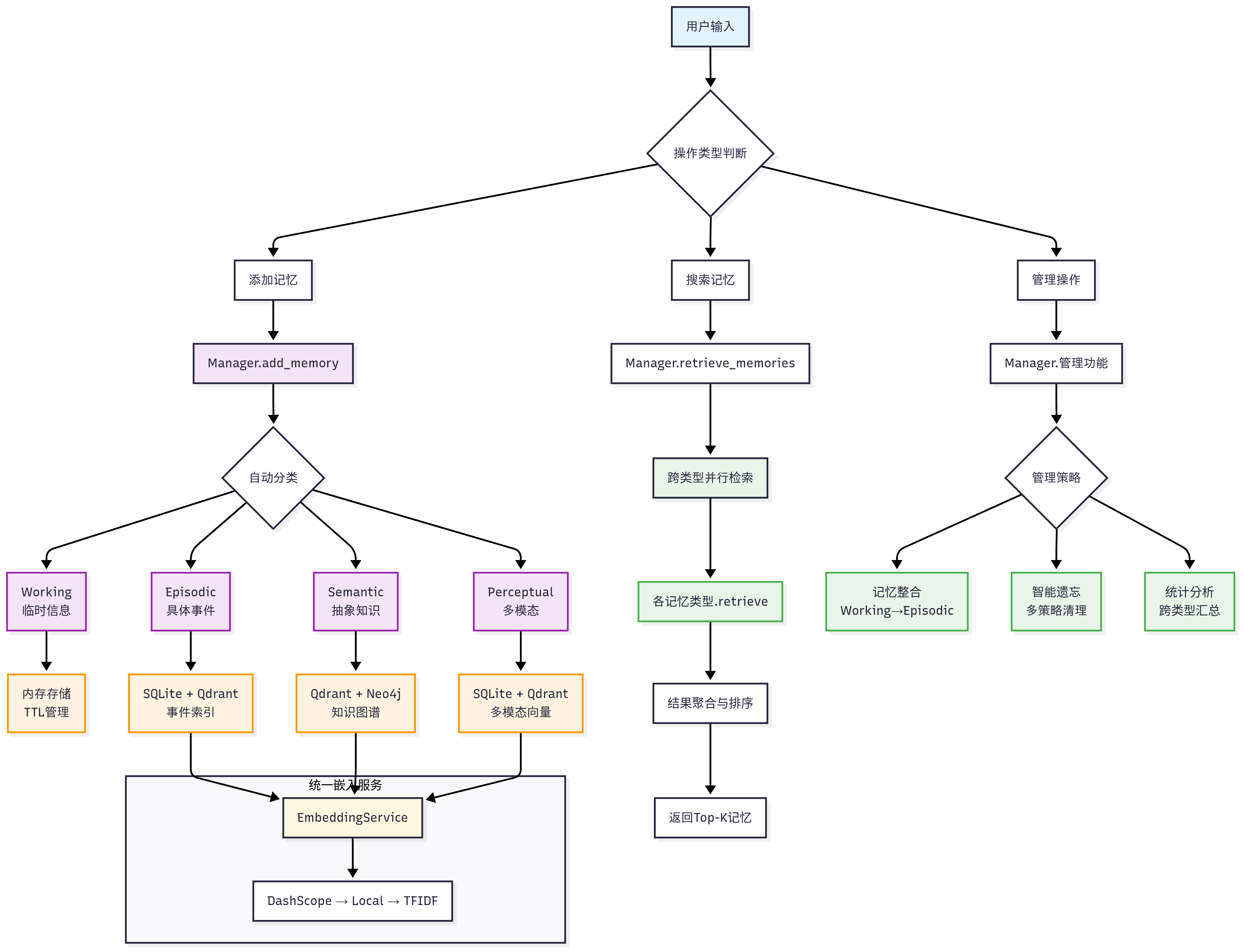
图 8.4 HelloAgents记忆系统的完整工作流程
我们的记忆系统由四种不同类型的记忆模块构成,每种模块都针对特定的应用场景和生命周期进行了优化:
首先是工作记忆 (Working Memory),它扮演着智能体“短期记忆”的角色,主要用于存储当前对话的上下文信息。为确保高速访问和响应,其容量被有意限制(例如,默认50条),并且生命周期与单个会话绑定,会话结束后便会自动清理。
其次是情景记忆 (Episodic Memory),它负责长期存储具体的交互事件和智能体的学习经历。与工作记忆不同,情景记忆包含了丰富的上下文信息,并支持按时间序列或主题进行回顾式检索,是智能体“复盘”和学习过往经验的基础。
与具体事件相对应的是语义记忆 (Semantic Memory),它存储的是更为抽象的知识、概念和规则。例如,通过对话了解到的用户偏好、需要长期遵守的指令或领域知识点,都适合存放在这里。这部分记忆具有高度的持久性和重要性,是智能体形成“知识体系”和进行关联推理的核心。
最后,为了与日益丰富的多媒体交互,我们引入了感知记忆 (Perceptual Memory)。该模块专门处理图像、音频等多模态信息,并支持跨模态检索。其生命周期会根据信息的重要性和可用存储空间进行动态管理。
### 8.2.2 快速体验:30秒上手记忆功能
在深入实现细节之前,让我们先快速体验一下记忆系统的基本功能:
```python
from hello_agents import SimpleAgent, HelloAgentsLLM, ToolRegistry
from hello_agents.tools import MemoryTool
# 创建具有记忆能力的Agent
llm = HelloAgentsLLM()
agent = SimpleAgent(name="记忆助手", llm=llm)
# 创建记忆工具
memory_tool = MemoryTool(user_id="user123")
tool_registry = ToolRegistry()
tool_registry.register_tool(memory_tool)
agent.tool_registry = tool_registry
# 体验记忆功能
print("=== 添加多个记忆 ===")
# 添加第一个记忆
result1 = memory_tool.execute("add", content="用户张三是一名Python开发者,专注于机器学习和数据分析", memory_type="semantic", importance=0.8)
print(f"记忆1: {result1}")
# 添加第二个记忆
result2 = memory_tool.execute("add", content="李四是前端工程师,擅长React和Vue.js开发", memory_type="semantic", importance=0.7)
print(f"记忆2: {result2}")
# 添加第三个记忆
result3 = memory_tool.execute("add", content="王五是产品经理,负责用户体验设计和需求分析", memory_type="semantic", importance=0.6)
print(f"记忆3: {result3}")
print("\n=== 搜索特定记忆 ===")
# 搜索前端相关的记忆
print("🔍 搜索 '前端工程师':")
result = memory_tool.execute("search", query="前端工程师", limit=3)
print(result)
print("\n=== 记忆摘要 ===")
result = memory_tool.execute("summary")
print(result)
```
### 8.2.3 MemoryTool详解
现在让我们采用自顶向下的方式,从MemoryTool支持的具体操作开始,逐步深入到底层实现。MemoryTool作为记忆系统的统一接口,其设计遵循了"统一入口,分发处理"的架构模式:
````python
def execute(self, action: str, **kwargs) -> str:
"""执行记忆操作
支持的操作:
- add: 添加记忆(支持4种类型: working/episodic/semantic/perceptual)
- search: 搜索记忆
- summary: 获取记忆摘要
- stats: 获取统计信息
- update: 更新记忆
- remove: 删除记忆
- forget: 遗忘记忆(多种策略)
- consolidate: 整合记忆(短期→长期)
- clear_all: 清空所有记忆
"""
if action == "add":
return self._add_memory(**kwargs)
elif action == "search":
return self._search_memory(**kwargs)
elif action == "summary":
return self._get_summary(**kwargs)
# ... 其他操作
````
这种统一的`execute`接口设计简化了Agent的调用方式,通过`action`参数指定具体操作,使用`kwargs`允许每个操作有不同的参数需求。在这里我们会将比较重要的几个操作罗列出来:
(1)操作1:add
`add`操作是记忆系统的基础,它模拟了人类大脑将感知信息编码为记忆的过程。在实现中,我们不仅要存储记忆内容,还要为每个记忆添加丰富的上下文信息,这些信息将在后续的检索和管理中发挥重要作用。
````python
def _add_memory(
self,
content: str = "",
memory_type: str = "working",
importance: float = 0.5,
file_path: str = None,
modality: str = None,
metadata
) -> str:
"""添加记忆"""
try:
# 确保会话ID存在
if self.current_session_id is None:
self.current_session_id = f"session_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
# 感知记忆文件支持
if memory_type == "perceptual" and file_path:
inferred = modality or self._infer_modality(file_path)
metadata.setdefault("modality", inferred)
metadata.setdefault("raw_data", file_path)
# 添加会话信息到元数据
metadata.update({
"session_id": self.current_session_id,
"timestamp": datetime.now().isoformat()
})
memory_id = self.memory_manager.add_memory(
content=content,
memory_type=memory_type,
importance=importance,
metadata=metadata,
auto_classify=False
)
return f"✅ 记忆已添加 (ID: {memory_id[:8]}...)"
except Exception as e:
return f"❌ 添加记忆失败: {str(e)}"
````
这里主要实现了三个关键任务:会话ID的自动管理(确保每个记忆都有明确的会话归属)、多模态数据的智能处理(自动推断文件类型并保存相关元数据)、以及上下文信息的自动补充(为每个记忆添加时间戳和会话信息)。其中,`importance`参数(默认0.5)用于标记记忆的重要程度,取值范围0.0-1.0,这个机制模拟了人类大脑对不同信息重要性的评估。这种设计让Agent能够自动区分不同时间段的对话,并为后续的检索和管理提供丰富的上下文信息。
其中,对每个记忆类型,我们提供了不同的使用示例:
```python
# 1. 工作记忆 - 临时信息,容量有限
memory_tool.execute("add",
content="用户刚才问了关于Python函数的问题",
memory_type="working",
importance=0.6
)
# 2. 情景记忆 - 具体事件和经历
memory_tool.execute("add",
content="2024年3月15日,用户张三完成了第一个Python项目",
memory_type="episodic",
importance=0.8,
event_type="milestone",
location="在线学习平台"
)
# 3. 语义记忆 - 抽象知识和概念
memory_tool.execute("add",
content="Python是一种解释型、面向对象的编程语言",
memory_type="semantic",
importance=0.9,
knowledge_type="factual"
)
# 4. 感知记忆 - 多模态信息
memory_tool.execute("add",
content="用户上传了一张Python代码截图,包含函数定义",
memory_type="perceptual",
importance=0.7,
modality="image",
file_path="./uploads/code_screenshot.png"
)
```
(2)操作2:search
`search`操作是记忆系统的核心功能,它需要在大量记忆中快速找到与查询最相关的内容。它涉及语义理解、相关性计算和结果排序等多个环节。
````python
def _search_memory(
self,
query: str,
limit: int = 5,
memory_types: List[str] = None,
memory_type: str = None,
min_importance: float = 0.1
) -> str:
"""搜索记忆"""
try:
# 参数标准化处理
if memory_type and not memory_types:
memory_types = [memory_type]
results = self.memory_manager.retrieve_memories(
query=query,
limit=limit,
memory_types=memory_types,
min_importance=min_importance
)
if not results:
return f"🔍 未找到与 '{query}' 相关的记忆"
# 格式化结果
formatted_results = []
formatted_results.append(f"🔍 找到 {len(results)} 条相关记忆:")
for i, memory in enumerate(results, 1):
memory_type_label = {
"working": "工作记忆",
"episodic": "情景记忆",
"semantic": "语义记忆",
"perceptual": "感知记忆"
}.get(memory.memory_type, memory.memory_type)
content_preview = memory.content[:80] + "..." if len(memory.content) > 80 else memory.content
formatted_results.append(
f"{i}. [{memory_type_label}] {content_preview} (重要性: {memory.importance:.2f})"
)
return "\n".join(formatted_results)
except Exception as e:
return f"❌ 搜索记忆失败: {str(e)}"
````
搜索操作在设计上支持单数和复数两种参数形式(`memory_type`和`memory_types`),让用户以最自然的方式表达需求。其中,`min_importance`参数(默认0.1)用于过滤低质量记忆。对于搜索功能的使用,可以参考这个示例。
```python
# 基础搜索
result = memory_tool.execute("search", query="Python编程", limit=5)
# 指定记忆类型搜索
result = memory_tool.execute("search",
query="学习进度",
memory_type="episodic",
limit=3
)
# 多类型搜索
result = memory_tool.execute("search",
query="函数定义",
memory_types=["semantic", "episodic"],
min_importance=0.5
)
```
(3)操作3:forget
遗忘机制是最具认知科学色彩的功能,它模拟人类大脑的选择性遗忘过程,支持三种策略:基于重要性(删除不重要的记忆)、基于时间(删除过时的记忆)和基于容量(当存储接近上限时删除最不重要的记忆)。
````python
def _forget(self, strategy: str = "importance_based", threshold: float = 0.1, max_age_days: int = 30) -> str:
"""遗忘记忆(支持多种策略)"""
try:
count = self.memory_manager.forget_memories(
strategy=strategy,
threshold=threshold,
max_age_days=max_age_days
)
return f"🧹 已遗忘 {count} 条记忆(策略: {strategy})"
except Exception as e:
return f"❌ 遗忘记忆失败: {str(e)}"
````
三种遗忘策略的使用:
```python
# 1. 基于重要性的遗忘 - 删除重要性低于阈值的记忆
memory_tool.execute("forget",
strategy="importance_based",
threshold=0.2
)
# 2. 基于时间的遗忘 - 删除超过指定天数的记忆
memory_tool.execute("forget",
strategy="time_based",
max_age_days=30
)
# 3. 基于容量的遗忘 - 当记忆数量超限时删除最不重要的
memory_tool.execute("forget",
strategy="capacity_based",
threshold=0.3
)
```
(4)操作4:consolidate
````python
def _consolidate(self, from_type: str = "working", to_type: str = "episodic", importance_threshold: float = 0.7) -> str:
"""整合记忆(将重要的短期记忆提升为长期记忆)"""
try:
count = self.memory_manager.consolidate_memories(
from_type=from_type,
to_type=to_type,
importance_threshold=importance_threshold,
)
return f"🔄 已整合 {count} 条记忆为长期记忆({from_type} → {to_type},阈值={importance_threshold})"
except Exception as e:
return f"❌ 整合记忆失败: {str(e)}"
````
consolidate操作借鉴了神经科学中的记忆固化概念,模拟人类大脑将短期记忆转化为长期记忆的过程。默认设置是将重要性超过0.7的工作记忆转换为情景记忆,这个阈值确保只有真正重要的信息才会被长期保存。整个过程是自动化的,用户无需手动选择具体的记忆,系统会智能地识别符合条件的记忆并执行类型转换。
记忆整合的使用示例:
```python
# 将重要的工作记忆转为情景记忆
memory_tool.execute("consolidate",
from_type="working",
to_type="episodic",
importance_threshold=0.7
)
# 将重要的情景记忆转为语义记忆
memory_tool.execute("consolidate",
from_type="episodic",
to_type="semantic",
importance_threshold=0.8
)
```
通过以上几个核心操作协作,MemoryTool构建了一个完整的记忆生命周期管理体系。从记忆的创建、检索、摘要到遗忘、整合和管理,形成了一个闭环的智能记忆管理系统,让Agent真正具备了类人的记忆能力。
### 8.2.4 MemoryManager详解
理解了MemoryTool的接口设计后,让我们深入到底层实现,看看MemoryTool是如何与MemoryManager协作的。这种分层设计体现了软件工程中的关注点分离原则,MemoryTool专注于用户接口和参数处理,而MemoryManager则负责核心的记忆管理逻辑。
MemoryTool在初始化时会创建一个MemoryManager实例,并根据配置启用不同类型的记忆模块。这种设计让用户可以根据具体需求选择启用哪些记忆类型,既保证了功能的完整性,又避免了不必要的资源消耗。
````python
class MemoryTool(Tool):
"""记忆工具 - 为Agent提供记忆功能"""
def __init__(
self,
user_id: str = "default_user",
memory_config: MemoryConfig = None,
memory_types: List[str] = None
):
super().__init__(
name="memory",
description="记忆工具 - 可以存储和检索对话历史、知识和经验"
)
# 初始化记忆管理器
self.memory_config = memory_config or MemoryConfig()
self.memory_types = memory_types or ["working", "episodic", "semantic"]
self.memory_manager = MemoryManager(
config=self.memory_config,
user_id=user_id,
enable_working="working" in self.memory_types,
enable_episodic="episodic" in self.memory_types,
enable_semantic="semantic" in self.memory_types,
enable_perceptual="perceptual" in self.memory_types
)
````
MemoryManager作为记忆系统的核心协调者,负责管理不同类型的记忆模块,并提供统一的操作接口。
````python
class MemoryManager:
"""记忆管理器 - 统一的记忆操作接口"""
def __init__(
self,
config: Optional[MemoryConfig] = None,
user_id: str = "default_user",
enable_working: bool = True,
enable_episodic: bool = True,
enable_semantic: bool = True,
enable_perceptual: bool = False
):
self.config = config or MemoryConfig()
self.user_id = user_id
# 初始化存储和检索组件
self.store = MemoryStore(self.config)
self.retriever = MemoryRetriever(self.store, self.config)
# 初始化各类型记忆
self.memory_types = {}
if enable_working:
self.memory_types['working'] = WorkingMemory(self.config, self.store)
if enable_episodic:
self.memory_types['episodic'] = EpisodicMemory(self.config, self.store)
if enable_semantic:
self.memory_types['semantic'] = SemanticMemory(self.config, self.store)
if enable_perceptual:
self.memory_types['perceptual'] = PerceptualMemory(self.config, self.store)
````
### 8.2.5 四种记忆类型
现在让我们深入了解四种记忆类型的具体实现,每种记忆类型都有其独特的特点和应用场景:
(1)工作记忆(WorkingMemory)
工作记忆是记忆系统中最活跃的部分,它负责存储当前对话会话中的临时信息。工作记忆的设计重点在于快速访问和自动清理,这种设计确保了系统的响应速度和资源效率。
工作记忆采用了纯内存存储方案,配合TTL(Time To Live)机制进行自动清理。这种设计的优势在于访问速度极快,但也意味着工作记忆的内容在系统重启后会丢失。这种特性正好符合工作记忆的定位,存储临时的、易变的信息。
````python
class WorkingMemory:
"""工作记忆实现
特点:
- 容量有限(默认50条)+ TTL自动清理
- 纯内存存储,访问速度极快
- 混合检索:TF-IDF向量化 + 关键词匹配
"""
def __init__(self, config: MemoryConfig):
self.max_capacity = config.working_memory_capacity or 50
self.max_age_minutes = config.working_memory_ttl or 60
self.memories = []
def add(self, memory_item: MemoryItem) -> str:
"""添加工作记忆"""
self._expire_old_memories() # 过期清理
if len(self.memories) >= self.max_capacity:
self._remove_lowest_priority_memory() # 容量管理
self.memories.append(memory_item)
return memory_item.id
def retrieve(self, query: str, limit: int = 5, **kwargs) -> List[MemoryItem]:
"""混合检索:TF-IDF向量化 + 关键词匹配"""
self._expire_old_memories()
# 尝试TF-IDF向量检索
vector_scores = self._try_tfidf_search(query)
# 计算综合分数
scored_memories = []
for memory in self.memories:
vector_score = vector_scores.get(memory.id, 0.0)
keyword_score = self._calculate_keyword_score(query, memory.content)
# 混合评分
base_relevance = vector_score * 0.7 + keyword_score * 0.3 if vector_score > 0 else keyword_score
time_decay = self._calculate_time_decay(memory.timestamp)
importance_weight = 0.8 + (memory.importance * 0.4)
final_score = base_relevance * time_decay * importance_weight
if final_score > 0:
scored_memories.append((final_score, memory))
scored_memories.sort(key=lambda x: x[0], reverse=True)
return [memory for _, memory in scored_memories[:limit]]
````
工作记忆的检索采用了混合检索策略,首先尝试使用TF-IDF向量化进行语义检索,如果失败则回退到关键词匹配。这种设计确保了在各种环境下都能提供可靠的检索服务。评分算法结合了语义相似度、时间衰减和重要性权重,最终得分公式为:`(相似度 × 时间衰减) × (0.8 + 重要性 × 0.4)`。
(2)情景记忆(EpisodicMemory)
情景记忆负责存储具体的事件和经历,它的设计重点在于保持事件的完整性和时间序列关系。情景记忆采用了SQLite+Qdrant的混合存储方案,SQLite负责结构化数据的存储和复杂查询,Qdrant负责高效的向量检索。
````python
class EpisodicMemory:
"""情景记忆实现
特点:
- SQLite+Qdrant混合存储架构
- 支持时间序列和会话级检索
- 结构化过滤 + 语义向量检索
"""
def __init__(self, config: MemoryConfig):
self.doc_store = SQLiteDocumentStore(config.database_path)
self.vector_store = QdrantVectorStore(config.qdrant_url, config.qdrant_api_key)
self.embedder = create_embedding_model_with_fallback()
self.sessions = {} # 会话索引
def add(self, memory_item: MemoryItem) -> str:
"""添加情景记忆"""
# 创建情景对象
episode = Episode(
episode_id=memory_item.id,
session_id=memory_item.metadata.get("session_id", "default"),
timestamp=memory_item.timestamp,
content=memory_item.content,
context=memory_item.metadata
)
# 更新会话索引
session_id = episode.session_id
if session_id not in self.sessions:
self.sessions[session_id] = []
self.sessions[session_id].append(episode.episode_id)
# 持久化存储(SQLite + Qdrant)
self._persist_episode(episode)
return memory_item.id
def retrieve(self, query: str, limit: int = 5, **kwargs) -> List[MemoryItem]:
"""混合检索:结构化过滤 + 语义向量检索"""
# 1. 结构化预过滤(时间范围、重要性等)
candidate_ids = self._structured_filter(**kwargs)
# 2. 向量语义检索
hits = self._vector_search(query, limit * 5, kwargs.get("user_id"))
# 3. 综合评分与排序
results = []
for hit in hits:
if self._should_include(hit, candidate_ids, kwargs):
score = self._calculate_episode_score(hit)
memory_item = self._create_memory_item(hit)
results.append((score, memory_item))
results.sort(key=lambda x: x[0], reverse=True)
return [item for _, item in results[:limit]]
def _calculate_episode_score(self, hit) -> float:
"""情景记忆评分算法"""
vec_score = float(hit.get("score", 0.0))
recency_score = self._calculate_recency(hit["metadata"]["timestamp"])
importance = hit["metadata"].get("importance", 0.5)
# 评分公式:(向量相似度 × 0.8 + 时间近因性 × 0.2) × 重要性权重
base_relevance = vec_score * 0.8 + recency_score * 0.2
importance_weight = 0.8 + (importance * 0.4)
return base_relevance * importance_weight
````
情景记忆的检索实现展现了复杂的多因素评分机制。它不仅考虑了语义相似度,还加入了时间近因性的考量,最终通过重要性权重进行调节。评分公式为:`(向量相似度 × 0.8 + 时间近因性 × 0.2) × (0.8 + 重要性 × 0.4)`,确保检索结果既语义相关又时间相关。
(3)语义记忆(SemanticMemory)
语义记忆是记忆系统中最复杂的部分,它负责存储抽象的概念、规则和知识。语义记忆的设计重点在于知识的结构化表示和智能推理能力。语义记忆采用了Neo4j图数据库和Qdrant向量数据库的混合架构,这种设计让系统既能进行快速的语义检索,又能利用知识图谱进行复杂的关系推理。
````python
class SemanticMemory(BaseMemory):
"""语义记忆实现
特点:
- 使用HuggingFace中文预训练模型进行文本嵌入
- 向量检索进行快速相似度匹配
- 知识图谱存储实体和关系
- 混合检索策略:向量+图+语义推理
"""
def __init__(self, config: MemoryConfig, storage_backend=None):
super().__init__(config, storage_backend)
# 嵌入模型(统一提供)
self.embedding_model = get_text_embedder()
# 专业数据库存储
self.vector_store = QdrantConnectionManager.get_instance(**qdrant_config)
self.graph_store = Neo4jGraphStore(**neo4j_config)
# 实体和关系缓存
self.entities: Dict[str, Entity] = {}
self.relations: List[Relation] = []
# NLP处理器(支持中英文)
self.nlp = self._init_nlp()
````
语义记忆的添加过程体现了知识图谱构建的完整流程。系统不仅存储记忆内容,还会自动提取实体和关系,构建结构化的知识表示:
```python
def add(self, memory_item: MemoryItem) -> str:
"""添加语义记忆"""
# 1. 生成文本嵌入
embedding = self.embedding_model.encode(memory_item.content)
# 2. 提取实体和关系
entities = self._extract_entities(memory_item.content)
relations = self._extract_relations(memory_item.content, entities)
# 3. 存储到Neo4j图数据库
for entity in entities:
self._add_entity_to_graph(entity, memory_item)
for relation in relations:
self._add_relation_to_graph(relation, memory_item)
# 4. 存储到Qdrant向量数据库
metadata = {
"memory_id": memory_item.id,
"entities": [e.entity_id for e in entities],
"entity_count": len(entities),
"relation_count": len(relations)
}
self.vector_store.add_vectors(
vectors=[embedding.tolist()],
metadata=[metadata],
ids=[memory_item.id]
)
```
语义记忆的检索实现了混合搜索策略,结合了向量检索的语义理解能力和图检索的关系推理能力:
```python
def retrieve(self, query: str, limit: int = 5, **kwargs) -> List[MemoryItem]:
"""检索语义记忆"""
# 1. 向量检索
vector_results = self._vector_search(query, limit * 2, user_id)
# 2. 图检索
graph_results = self._graph_search(query, limit * 2, user_id)
# 3. 混合排序
combined_results = self._combine_and_rank_results(
vector_results, graph_results, query, limit
)
return combined_results[:limit]
```
混合排序算法采用了多因素评分机制:
```python
def _combine_and_rank_results(self, vector_results, graph_results, query, limit):
"""混合排序结果"""
combined = {}
# 合并向量和图检索结果
for result in vector_results:
combined[result["memory_id"]] = {
**result,
"vector_score": result.get("score", 0.0),
"graph_score": 0.0
}
for result in graph_results:
memory_id = result["memory_id"]
if memory_id in combined:
combined[memory_id]["graph_score"] = result.get("similarity", 0.0)
else:
combined[memory_id] = {
**result,
"vector_score": 0.0,
"graph_score": result.get("similarity", 0.0)
}
# 计算混合分数
for memory_id, result in combined.items():
vector_score = result["vector_score"]
graph_score = result["graph_score"]
importance = result.get("importance", 0.5)
# 基础相似度得分
base_relevance = vector_score * 0.7 + graph_score * 0.3
# 重要性权重 [0.8, 1.2]
importance_weight = 0.8 + (importance * 0.4)
# 最终得分:相似度 * 重要性权重
combined_score = base_relevance * importance_weight
result["combined_score"] = combined_score
# 排序并返回
sorted_results = sorted(
combined.values(),
key=lambda x: x["combined_score"],
reverse=True
)
return sorted_results[:limit]
```
语义记忆的评分公式为:`(向量相似度 × 0.7 + 图相似度 × 0.3) × (0.8 + 重要性 × 0.4)`。这种设计的核心思想是:
- 向量检索权重(0.7):语义相似度是主要因素,确保检索结果与查询语义相关
- 图检索权重(0.3):关系推理作为补充,发现概念间的隐含关联
- 重要性权重范围[0.8, 1.2]:避免重要性过度影响相似度排序,保持检索的准确性
(4)感知记忆(PerceptualMemory)
感知记忆支持文本、图像、音频等多种模态的数据存储和检索。它采用了模态分离的存储策略,为不同模态的数据创建独立的向量集合,这种设计避免了维度不匹配的问题,同时保证了检索的准确性:
````python
class PerceptualMemory(BaseMemory):
"""感知记忆实现
特点:
- 支持多模态数据(文本、图像、音频等)
- 跨模态相似性搜索
- 感知数据的语义理解
- 支持内容生成和检索
"""
def __init__(self, config: MemoryConfig, storage_backend=None):
super().__init__(config, storage_backend)
# 多模态编码器
self.text_embedder = get_text_embedder()
self._clip_model = self._init_clip_model() # 图像编码
self._clap_model = self._init_clap_model() # 音频编码
# 按模态分离的向量存储
self.vector_stores = {
"text": QdrantConnectionManager.get_instance(
collection_name="perceptual_text",
vector_size=self.vector_dim
),
"image": QdrantConnectionManager.get_instance(
collection_name="perceptual_image",
vector_size=self._image_dim
),
"audio": QdrantConnectionManager.get_instance(
collection_name="perceptual_audio",
vector_size=self._audio_dim
)
}
````
感知记忆的检索支持同模态和跨模态两种模式。同模态检索利用专业的编码器进行精确匹配,而跨模态检索则需要更复杂的语义对齐机制:
```python
def retrieve(self, query: str, limit: int = 5, **kwargs) -> List[MemoryItem]:
"""检索感知记忆(可筛模态;同模态向量检索+时间/重要性融合)"""
user_id = kwargs.get("user_id")
target_modality = kwargs.get("target_modality")
query_modality = kwargs.get("query_modality", target_modality or "text")
# 同模态向量检索
try:
query_vector = self._encode_data(query, query_modality)
store = self._get_vector_store_for_modality(target_modality or query_modality)
where = {"memory_type": "perceptual"}
if user_id:
where["user_id"] = user_id
if target_modality:
where["modality"] = target_modality
hits = store.search_similar(
query_vector=query_vector,
limit=max(limit * 5, 20),
where=where
)
except Exception:
hits = []
# 融合排序(向量相似度 + 时间近因性 + 重要性权重)
results = []
for hit in hits:
vector_score = float(hit.get("score", 0.0))
recency_score = self._calculate_recency_score(hit["metadata"]["timestamp"])
importance = hit["metadata"].get("importance", 0.5)
# 评分算法
base_relevance = vector_score * 0.8 + recency_score * 0.2
importance_weight = 0.8 + (importance * 0.4)
combined_score = base_relevance * importance_weight
results.append((combined_score, self._create_memory_item(hit)))
results.sort(key=lambda x: x[0], reverse=True)
return [item for _, item in results[:limit]]
```
感知记忆的评分公式为:`(向量相似度 × 0.8 + 时间近因性 × 0.2) × (0.8 + 重要性 × 0.4)`。感知记忆的评分机制还支持跨模态检索,通过统一的向量空间实现文本、图像、音频等不同模态数据的语义对齐。当进行跨模态检索时,系统会自动调整评分权重,确保检索结果的多样性和准确性。此外,感知记忆中的时间近因性计算采用了指数衰减模型:
```python
def _calculate_recency_score(self, timestamp: str) -> float:
"""计算时间近因性得分"""
try:
memory_time = datetime.fromisoformat(timestamp)
current_time = datetime.now()
age_hours = (current_time - memory_time).total_seconds() / 3600
# 指数衰减:24小时内保持高分,之后逐渐衰减
decay_factor = 0.1 # 衰减系数
recency_score = math.exp(-decay_factor * age_hours / 24)
return max(0.1, recency_score) # 最低保持0.1的基础分数
except Exception:
return 0.5 # 默认中等分数
```
这种时间衰减模型模拟了人类记忆中的遗忘曲线,确保了感知记忆系统能够优先检索到时间上更相关的记忆内容。
## 8.3 RAG系统:知识检索增强
### 8.3.1 RAG的基础知识
在深入HelloAgents的RAG系统实现之前,让我们先了解RAG技术的基础概念、发展历程和核心原理。由于本文内容不是以RAG为基础进行创作,为此这里只帮读者快速梳理相关概念,以便更好地理解系统设计的技术选择和创新点。
(1)什么是RAG?
检索增强生成(Retrieval-Augmented Generation,RAG)是一种结合了信息检索和文本生成的技术。它的核心思想是:在生成回答之前,先从外部知识库中检索相关信息,然后将检索到的信息作为上下文提供给大语言模型,从而生成更准确、更可靠的回答。
因此,检索增强生成可以拆分为三个词汇。检索是指从知识库中查询相关内容;增强是将检索结果融入提示词,辅助模型生成;生成则输出兼具准确性与透明度的答案。
(2)基本工作流程
一个完整的RAG应用流程主要分为两大核心环节。在数据准备阶段,系统通过数据提取、文本分割和向量化,将外部知识构建成一个可检索的数据库。随后在应用阶段,系统会响应用户的提问,从数据库中检索相关信息,将其注入Prompt,并最终驱动大语言模型生成答案。
(3)发展历程
第一阶段:朴素RAG(Naive RAG, 2020-2021)。这是RAG技术的萌芽阶段,其流程直接而简单,通常被称为“检索-读取”(Retrieve-Read)模式。检索方式:主要依赖传统的关键词匹配算法,如`TF-IDF`或`BM25`。这些方法计算词频和文档频率来评估相关性,对字面匹配效果好,但难以理解语义上的相似性。生成模式:将检索到的文档内容不加处理地直接拼接到提示词的上下文中,然后送给生成模型。
第二阶段:高级RAG(Advanced RAG, 2022-2023)。随着向量数据库和文本嵌入技术的成熟,RAG进入了快速发展阶段。研究者和开发者们在“检索”和“生成”的各个环节引入了大量优化技术。检索方式:转向基于稠密嵌入(Dense Embedding)的语义检索。通过将文本转换为高维向量,模型能够理解和匹配语义上的相似性,而不仅仅是关键词。生成模式:引入了很多优化技术,例如查询重写,文档分块,重排序等。
第三阶段:模块化RAG(Modular RAG, 2023-至今)。在高级RAG的基础上,现代RAG系统进一步向着模块化、自动化和智能化的方向发展。系统的各个部分被设计成可插拔、可组合的独立模块,以适应更多样化和复杂的应用场景。检索方式:如混合检索,多查询扩展,假设性文档嵌入等。生成模式:思维链推理,自我反思与修正等。
### 8.3.2 RAG系统工作原理
在深入实现细节之前,可以通过流程图来梳理Helloagents的RAG系统完整工作流程:
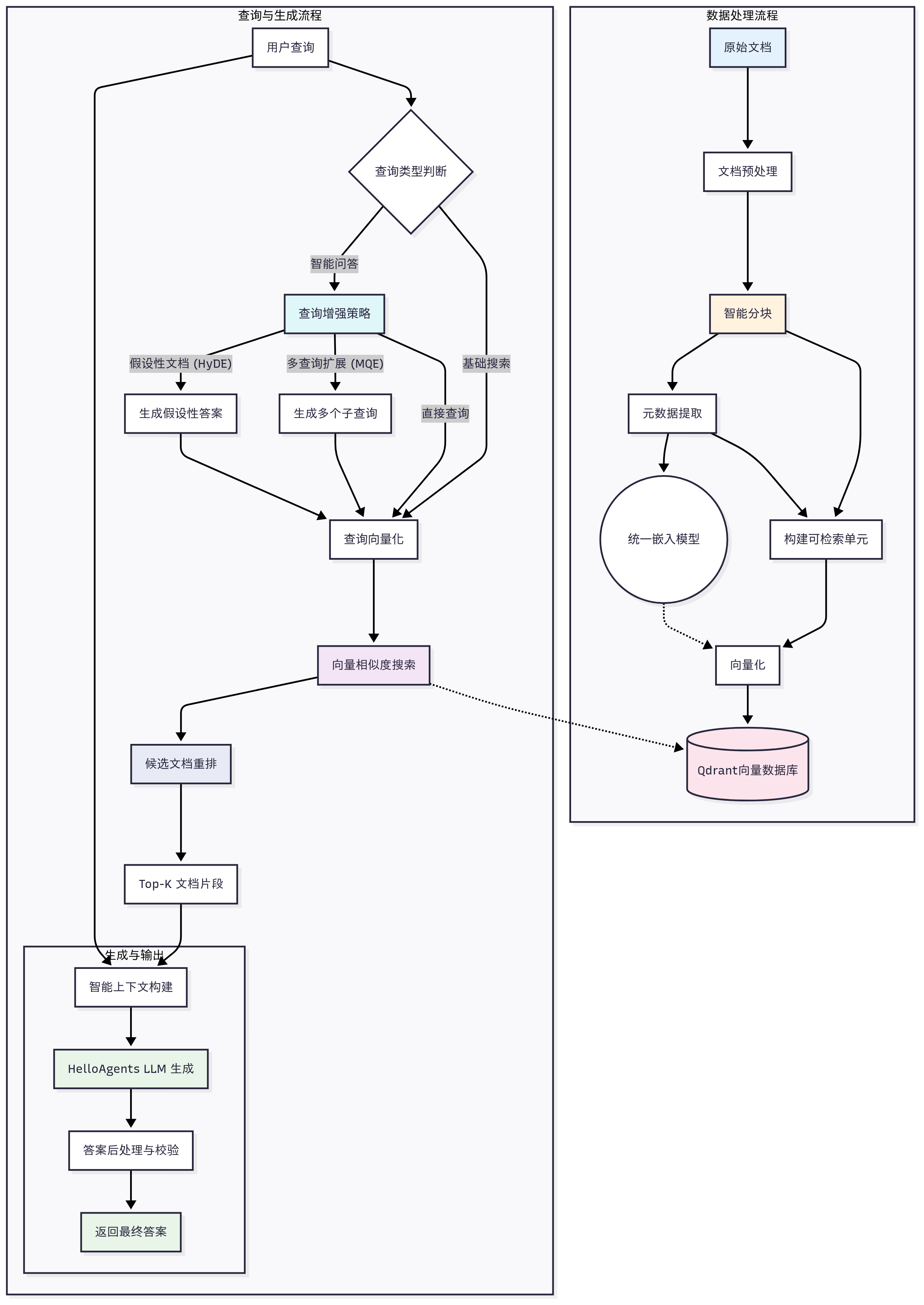
图 8.5 RAG系统的核心工作原理
如图8.5所示,展示了RAG系统的两个主要工作模式:
1. 数据处理流程:处理和存储知识文档,在这里我们采取工具`Markitdown`,设计思路是将传入的一切外部知识源统一转化为Markdown格式进行处理。
2. 查询与生成流程:根据查询检索相关信息并生成回答。
### 8.3.3 快速体验:30秒上手RAG功能
让我们先快速体验一下RAG系统的基本功能:
```python
from hello_agents import SimpleAgent, HelloAgentsLLM, ToolRegistry
from hello_agents.tools import RAGTool
# 创建具有RAG能力的Agent
llm = HelloAgentsLLM()
agent = SimpleAgent(name="知识助手", llm=llm)
# 创建RAG工具
rag_tool = RAGTool(
knowledge_base_path="./knowledge_base",
collection_name="test_collection",
rag_namespace="test"
)
tool_registry = ToolRegistry()
tool_registry.register_tool(rag_tool)
agent.tool_registry = tool_registry
# 体验RAG功能
# 添加第一个知识
result1 = rag_tool.execute("add_text",
text="Python是一种高级编程语言,由Guido van Rossum于1991年首次发布。Python的设计哲学强调代码的可读性和简洁的语法。",
document_id="python_intro")
print(f"知识1: {result1}")
# 添加第二个知识
result2 = rag_tool.execute("add_text",
text="机器学习是人工智能的一个分支,通过算法让计算机从数据中学习模式。主要包括监督学习、无监督学习和强化学习三种类型。",
document_id="ml_basics")
print(f"知识2: {result2}")
# 添加第三个知识
result3 = rag_tool.execute("add_text",
text="RAG(检索增强生成)是一种结合信息检索和文本生成的AI技术。它通过检索相关知识来增强大语言模型的生成能力。",
document_id="rag_concept")
print(f"知识3: {result3}")
print("\n=== 搜索知识 ===")
result = rag_tool.execute("search",
query="Python编程语言的历史",
limit=3,
min_score=0.1
)
print(result)
print("\n=== 知识库统计 ===")
result = rag_tool.execute("stats")
print(result)
```
接下来,我们将深入探讨HelloAgents RAG系统的具体实现。
### 8.3.4 RAG系统架构设计
在这一节中,我们采取与记忆系统不同的方式讲解。因为`Memory_tool`是系统性的实现,而RAG在我们的设计中被定义为一种工具,可以梳理为一条pipeline。我们的RAG系统的核心架构可以概括为"五层七步"的设计模式:
```
用户层:RAGTool统一接口
↓
应用层:智能问答、搜索、管理
↓
处理层:文档解析、分块、向量化
↓
存储层:向量数据库、文档存储
↓
基础层:嵌入模型、LLM、数据库
```
这种分层设计的优势在于每一层都可以独立优化和替换,同时保持整体系统的稳定性。例如,可以轻松地将嵌入模型从sentence-transformers切换到百炼API,而不影响上层的业务逻辑。同样的,这些处理的流程代码是完全可复用的,也可以选取自己需要的部分放进自己的项目中。RAGTool作为RAG系统的统一入口,提供了简洁的API接口。
````python
class RAGTool(Tool):
"""RAG工具
提供完整的 RAG 能力:
- 添加多格式文档(PDF、Office、图片、音频等)
- 智能检索与召回
- LLM 增强问答
- 知识库管理
"""
def __init__(
self,
knowledge_base_path: str = "./knowledge_base",
qdrant_url: str = None,
qdrant_api_key: str = None,
collection_name: str = "rag_knowledge_base",
rag_namespace: str = "default"
):
# 初始化RAG管道
self._pipelines: Dict[str, Dict[str, Any]] = {}
self.llm = HelloAgentsLLM()
# 创建默认管道
default_pipeline = create_rag_pipeline(
qdrant_url=self.qdrant_url,
qdrant_api_key=self.qdrant_api_key,
collection_name=self.collection_name,
rag_namespace=self.rag_namespace
)
self._pipelines[self.rag_namespace] = default_pipeline
````
整个处理流程如下所示:
```
任意格式文档 → MarkItDown转换 → Markdown文本 → 智能分块 → 向量化 → 存储检索
```
(1)多模态文档载入
RAG系统的核心优势之一是其强大的多模态文档处理能力。系统使用MarkItDown作为统一的文档转换引擎,支持几乎所有常见的文档格式。MarkItDown是微软开源的通用文档转换工具,它是HelloAgents RAG系统的核心组件,负责将任意格式的文档统一转换为结构化的Markdown文本。无论输入是PDF、Word、Excel、图片还是音频,最终都会转换为标准的Markdown格式,然后进入统一的分块、向量化和存储流程。
```python
def _convert_to_markdown(path: str) -> str:
"""
Universal document reader using MarkItDown with enhanced PDF processing.
核心功能:将任意格式文档转换为Markdown文本
支持格式:
- 文档:PDF、Word、Excel、PowerPoint
- 图像:JPG、PNG、GIF(通过OCR)
- 音频:MP3、WAV、M4A(通过转录)
- 文本:TXT、CSV、JSON、XML、HTML
- 代码:Python、JavaScript、Java等
"""
if not os.path.exists(path):
return ""
# 对PDF文件使用增强处理
ext = (os.path.splitext(path)[1] or '').lower()
if ext == '.pdf':
return _enhanced_pdf_processing(path)
# 其他格式使用MarkItDown统一转换
md_instance = _get_markitdown_instance()
if md_instance is None:
return _fallback_text_reader(path)
try:
result = md_instance.convert(path)
markdown_text = getattr(result, "text_content", None)
if isinstance(markdown_text, str) and markdown_text.strip():
print(f"[RAG] MarkItDown转换成功: {path} -> {len(markdown_text)} chars Markdown")
return markdown_text
return ""
except Exception as e:
print(f"[WARNING] MarkItDown转换失败 {path}: {e}")
return _fallback_text_reader(path)
```
(2)智能分块策略
经过MarkItDown转换后,所有文档都统一为标准的Markdown格式。这为后续的智能分块提供了结构化的基础。HelloAgents实现了专门针对Markdown格式的智能分块策略,充分利用Markdown的结构化特性进行精确分割。
Markdown结构感知的分块流程:
```
标准Markdown文本 → 标题层次解析 → 段落语义分割 → Token计算分块 → 重叠策略优化 → 向量化准备
↓ ↓ ↓ ↓ ↓ ↓
统一格式 #/##/### 语义边界 大小控制 信息连续性 嵌入向量
结构清晰 层次识别 完整性保证 检索优化 上下文保持 相似度匹配
```
由于所有文档都已转换为Markdown格式,系统可以利用Markdown的标题结构(#、##、###等)进行精确的语义分割:
```python
def _split_paragraphs_with_headings(text: str) -> List[Dict]:
"""根据标题层次分割段落,保持语义完整性"""
lines = text.splitlines()
heading_stack: List[str] = []
paragraphs: List[Dict] = []
buf: List[str] = []
char_pos = 0
def flush_buf(end_pos: int):
if not buf:
return
content = "\n".join(buf).strip()
if not content:
return
paragraphs.append({
"content": content,
"heading_path": " > ".join(heading_stack) if heading_stack else None,
"start": max(0, end_pos - len(content)),
"end": end_pos,
})
for ln in lines:
raw = ln
if raw.strip().startswith("#"):
# 处理标题行
flush_buf(char_pos)
level = len(raw) - len(raw.lstrip('#'))
title = raw.lstrip('#').strip()
if level <= 0:
level = 1
if level <= len(heading_stack):
heading_stack = heading_stack[:level-1]
heading_stack.append(title)
char_pos += len(raw) + 1
continue
# 段落内容累积
if raw.strip() == "":
flush_buf(char_pos)
buf = []
else:
buf.append(raw)
char_pos += len(raw) + 1
flush_buf(char_pos)
if not paragraphs:
paragraphs = [{"content": text, "heading_path": None, "start": 0, "end": len(text)}]
return paragraphs
```
在Markdown段落分割的基础上,系统进一步根据Token数量进行智能分块。由于输入已经是结构化的Markdown文本,系统可以更精确地控制分块边界,确保每个分块既适合向量化处理,又保持Markdown结构的完整性:
```python
def _chunk_paragraphs(paragraphs: List[Dict], chunk_tokens: int, overlap_tokens: int) -> List[Dict]:
"""基于Token数量的智能分块"""
chunks: List[Dict] = []
cur: List[Dict] = []
cur_tokens = 0
i = 0
while i < len(paragraphs):
p = paragraphs[i]
p_tokens = _approx_token_len(p["content"]) or 1
if cur_tokens + p_tokens <= chunk_tokens or not cur:
cur.append(p)
cur_tokens += p_tokens
i += 1
else:
# 生成当前分块
content = "\n\n".join(x["content"] for x in cur)
start = cur[0]["start"]
end = cur[-1]["end"]
heading_path = next((x["heading_path"] for x in reversed(cur) if x.get("heading_path")), None)
chunks.append({
"content": content,
"start": start,
"end": end,
"heading_path": heading_path,
})
# 构建重叠部分
if overlap_tokens > 0 and cur:
kept: List[Dict] = []
kept_tokens = 0
for x in reversed(cur):
t = _approx_token_len(x["content"]) or 1
if kept_tokens + t > overlap_tokens:
break
kept.append(x)
kept_tokens += t
cur = list(reversed(kept))
cur_tokens = kept_tokens
else:
cur = []
cur_tokens = 0
# 处理最后一个分块
if cur:
content = "\n\n".join(x["content"] for x in cur)
start = cur[0]["start"]
end = cur[-1]["end"]
heading_path = next((x["heading_path"] for x in reversed(cur) if x.get("heading_path")), None)
chunks.append({
"content": content,
"start": start,
"end": end,
"heading_path": heading_path,
})
return chunks
```
同时为了兼容不同语言,系统实现了针对中英文混合文本的Token估算算法,这对于准确控制分块大小至关重要:
```python
def _approx_token_len(text: str) -> int:
"""近似估计Token长度,支持中英文混合"""
# CJK字符按1 token计算
cjk = sum(1 for ch in text if _is_cjk(ch))
# 其他字符按空白分词计算
non_cjk_tokens = len([t for t in text.split() if t])
return cjk + non_cjk_tokens
def _is_cjk(ch: str) -> bool:
"""判断是否为CJK字符"""
code = ord(ch)
return (
0x4E00 <= code <= 0x9FFF or # CJK统一汉字
0x3400 <= code <= 0x4DBF or # CJK扩展A
0x20000 <= code <= 0x2A6DF or # CJK扩展B
0x2A700 <= code <= 0x2B73F or # CJK扩展C
0x2B740 <= code <= 0x2B81F or # CJK扩展D
0x2B820 <= code <= 0x2CEAF or # CJK扩展E
0xF900 <= code <= 0xFAFF # CJK兼容汉字
)
```
(3)统一嵌入与向量存储
嵌入模型是RAG系统的核心,它负责将文本转换为高维向量,使得计算机能够理解和比较文本的语义相似性。RAG系统的检索能力很大程度上取决于嵌入模型的质量和向量存储的效率。HelloAgents实现了统一的嵌入接口。在这里为了演示,使用百炼API,如果尚未配置可以切换为本地的`all-MiniLM-L6-v2`模型,如果两种方案都不支持,也配置了TF-IDF算法来兜底。实际使用可以替换为自己想要的模型或者API,也可以尝试去扩展框架内容~
```python
def index_chunks(
store = None,
chunks: List[Dict] = None,
cache_db: Optional[str] = None,
batch_size: int = 64,
rag_namespace: str = "default"
) -> None:
"""
Index markdown chunks with unified embedding and Qdrant storage.
Uses百炼 API with fallback to sentence-transformers.
"""
if not chunks:
print("[RAG] No chunks to index")
return
# 使用统一嵌入模型
embedder = get_text_embedder()
dimension = get_dimension(384)
# 创建默认Qdrant存储
if store is None:
store = _create_default_vector_store(dimension)
print(f"[RAG] Created default Qdrant store with dimension {dimension}")
# 预处理Markdown文本以获得更好的嵌入质量
processed_texts = []
for c in chunks:
raw_content = c["content"]
processed_content = _preprocess_markdown_for_embedding(raw_content)
processed_texts.append(processed_content)
print(f"[RAG] Embedding start: total_texts={len(processed_texts)} batch_size={batch_size}")
# 批量编码
vecs: List[List[float]] = []
for i in range(0, len(processed_texts), batch_size):
part = processed_texts[i:i+batch_size]
try:
# 使用统一嵌入器(内部处理缓存)
part_vecs = embedder.encode(part)
# 标准化为List[List[float]]格式
if not isinstance(part_vecs, list):
if hasattr(part_vecs, "tolist"):
part_vecs = [part_vecs.tolist()]
else:
part_vecs = [list(part_vecs)]
# 处理向量格式和维度
for v in part_vecs:
try:
if hasattr(v, "tolist"):
v = v.tolist()
v_norm = [float(x) for x in v]
# 维度检查和调整
if len(v_norm) != dimension:
print(f"[WARNING] 向量维度异常: 期望{dimension}, 实际{len(v_norm)}")
if len(v_norm) < dimension:
v_norm.extend([0.0] * (dimension - len(v_norm)))
else:
v_norm = v_norm[:dimension]
vecs.append(v_norm)
except Exception as e:
print(f"[WARNING] 向量转换失败: {e}, 使用零向量")
vecs.append([0.0] * dimension)
except Exception as e:
print(f"[WARNING] Batch {i} encoding failed: {e}")
# 实现重试机制
# ... 重试逻辑 ...
print(f"[RAG] Embedding progress: {min(i+batch_size, len(processed_texts))}/{len(processed_texts)}")
```
### 8.3.5 高级检索策略
RAG系统的检索能力是其核心竞争力。在实际应用中,用户的查询表述与文档中的实际内容可能存在用词差异,导致相关文档无法被检索到。为了解决这个问题,HelloAgents实现了三种互补的高级检索策略:多查询扩展(MQE)、假设文档嵌入(HyDE)和统一的扩展检索框架。
(1)多查询扩展(MQE)
多查询扩展(Multi-Query Expansion)是一种通过生成语义等价的多样化查询来提高检索召回率的技术。这种方法的核心洞察是:同一个问题可以有多种不同的表述方式,而不同的表述可能匹配到不同的相关文档。例如,"如何学习Python"可以扩展为"Python入门教程"、"Python学习方法"、"Python编程指南"等多个查询。通过并行执行这些扩展查询并合并结果,系统能够覆盖更广泛的相关文档,避免因用词差异而遗漏重要信息。
MQE的优势在于它能够自动理解用户查询的多种可能含义,特别是对于模糊查询或专业术语查询效果显著。系统使用LLM生成扩展查询,确保扩展的多样性和语义相关性:
```python
def _prompt_mqe(query: str, n: int) -> List[str]:
"""使用LLM生成多样化的查询扩展"""
try:
from ...core.llm import HelloAgentsLLM
llm = HelloAgentsLLM()
prompt = [
{"role": "system", "content": "你是检索查询扩展助手。生成语义等价或互补的多样化查询。使用中文,简短,避免标点。"},
{"role": "user", "content": f"原始查询:{query}\n请给出{n}个不同表述的查询,每行一个。"}
]
text = llm.invoke(prompt)
lines = [ln.strip("- \t") for ln in (text or "").splitlines()]
outs = [ln for ln in lines if ln]
return outs[:n] or [query]
except Exception:
return [query]
```
(2)假设文档嵌入(HyDE)
假设文档嵌入(Hypothetical Document Embeddings,HyDE)是一种创新的检索技术,它的核心思想是"用答案找答案"。传统的检索方法是用问题去匹配文档,但问题和答案在语义空间中的分布往往存在差异——问题通常是疑问句,而文档内容是陈述句。HyDE通过让LLM先生成一个假设性的答案段落,然后用这个答案段落去检索真实文档,从而缩小了查询和文档之间的语义鸿沟。
这种方法的优势在于,假设答案与真实答案在语义空间中更加接近,因此能够更准确地匹配到相关文档。即使假设答案的内容不完全正确,它所包含的关键术语、概念和表述风格也能有效引导检索系统找到正确的文档。特别是对于专业领域的查询,HyDE能够生成包含领域术语的假设文档,显著提升检索精度:
```python
def _prompt_hyde(query: str) -> Optional[str]:
"""生成假设性文档用于改善检索"""
try:
from ...core.llm import HelloAgentsLLM
llm = HelloAgentsLLM()
prompt = [
{"role": "system", "content": "根据用户问题,先写一段可能的答案性段落,用于向量检索的查询文档(不要分析过程)。"},
{"role": "user", "content": f"问题:{query}\n请直接写一段中等长度、客观、包含关键术语的段落。"}
]
return llm.invoke(prompt)
except Exception:
return None
```
(3)扩展检索框架
HelloAgents将MQE和HyDE两种策略整合到统一的扩展检索框架中。系统通过`enable_mqe`和`enable_hyde`参数让用户可以根据具体场景选择启用哪些策略:对于需要高召回率的场景可以同时启用两种策略,对于性能敏感的场景可以只使用基础检索。
扩展检索的核心机制是"扩展-检索-合并"三步流程。首先,系统根据原始查询生成多个扩展查询(包括MQE生成的多样化查询和HyDE生成的假设文档);然后,对每个扩展查询并行执行向量检索,获取候选文档池;最后,通过去重和分数排序合并所有结果,返回最相关的top-k文档。这种设计的巧妙之处在于,它通过`candidate_pool_multiplier`参数(默认为4)扩大候选池,确保有足够的候选文档进行筛选,同时通过智能去重避免返回重复内容。
```python
def search_vectors_expanded(
store = None,
query: str = "",
top_k: int = 8,
rag_namespace: Optional[str] = None,
only_rag_data: bool = True,
score_threshold: Optional[float] = None,
enable_mqe: bool = False,
mqe_expansions: int = 2,
enable_hyde: bool = False,
candidate_pool_multiplier: int = 4,
) -> List[Dict]:
"""
Search with query expansion using unified embedding and Qdrant.
"""
if not query:
return []
# 创建默认存储
if store is None:
store = _create_default_vector_store()
# 查询扩展
expansions: List[str] = [query]
if enable_mqe and mqe_expansions > 0:
expansions.extend(_prompt_mqe(query, mqe_expansions))
if enable_hyde:
hyde_text = _prompt_hyde(query)
if hyde_text:
expansions.append(hyde_text)
# 去重和修剪
uniq: List[str] = []
for e in expansions:
if e and e not in uniq:
uniq.append(e)
expansions = uniq[: max(1, len(uniq))]
# 分配候选池
pool = max(top_k * candidate_pool_multiplier, 20)
per = max(1, pool // max(1, len(expansions)))
# 构建RAG数据过滤器
where = {"memory_type": "rag_chunk"}
if only_rag_data:
where["is_rag_data"] = True
where["data_source"] = "rag_pipeline"
if rag_namespace:
where["rag_namespace"] = rag_namespace
# 收集所有扩展查询的结果
agg: Dict[str, Dict] = {}
for q in expansions:
qv = embed_query(q)
hits = store.search_similar(
query_vector=qv,
limit=per,
score_threshold=score_threshold,
where=where
)
for h in hits:
mid = h.get("metadata", {}).get("memory_id", h.get("id"))
s = float(h.get("score", 0.0))
if mid not in agg or s > float(agg[mid].get("score", 0.0)):
agg[mid] = h
# 按分数排序返回
merged = list(agg.values())
merged.sort(key=lambda x: float(x.get("score", 0.0)), reverse=True)
return merged[:top_k]
```
实际应用中,这三种策略的组合使用效果最佳。MQE擅长处理用词多样性问题,HyDE擅长处理语义鸿沟问题,而统一框架则确保了结果的质量和多样性。对于一般查询,建议启用MQE;对于专业领域查询,建议同时启用MQE和HyDE;对于性能敏感场景,可以只使用基础检索或仅启用MQE。
当然还有很多有趣的方法,这里只是为大家适当的扩展介绍,在实际的使用场景里也需要去尝试寻找适合问题的解决方案。
## 8.4 构建智能文档问答助手
在前面的章节中,我们详细介绍了HelloAgents的记忆系统和RAG系统的设计与实现。现在,让我们通过一个完整的实战案例,展示如何将这两个系统有机结合,构建一个智能文档问答助手。
### 8.4.1 案例背景与目标
在实际工作中,我们经常需要处理大量的技术文档、研究论文、产品手册等PDF文件。传统的文档阅读方式效率低下,难以快速定位关键信息,更无法建立知识间的关联。
本案例将基于Datawhale另外一门动手学大模型教程Happy-LLM的公测PDF文档`Happy-LLM-0727.pdf`为例,构建一个基于Gradio的Web应用,展示如何使用RAGTool和MemoryTool构建完整的交互式学习助手。PDF可在这个[链接](https://github.com/datawhalechina/happy-llm/releases/download/v1.0.1/Happy-LLM-0727.pdf)获取。
我们希望实现以下功能:
1. 智能文档处理:使用MarkItDown实现PDF到Markdown的统一转换,基于Markdown结构的智能分块策略,高效的向量化和索引构建
2. 高级检索问答:多查询扩展(MQE)提升召回率,假设文档嵌入(HyDE)改善检索精度,上下文感知的智能问答
3. 多层次记忆管理:工作记忆管理当前学习任务和上下文,情景记忆记录学习事件和查询历史,语义记忆存储概念知识和理解,感知记忆处理文档特征和多模态信息
4. 个性化学习支持:基于学习历史的个性化推荐,记忆整合和选择性遗忘,学习报告生成和进度追踪
为了更清晰地展示整个系统的工作流程,图8.6展示了五个步骤之间的关系和数据流动。五个步骤形成了一个完整的闭环:步骤1将PDF文档处理后的信息记录到记忆系统,步骤2的检索结果也会记录到记忆系统,步骤3展示记忆系统的完整功能(添加、检索、整合、遗忘),步骤4整合RAG和Memory提供智能路由,步骤5收集所有统计信息生成学习报告。

图 8.6 智能问答助手的五步执行流程
接下来,我们将展示如何实现这个Web应用。整个应用分为三个核心部分:
1. 核心助手类(PDFLearningAssistant):封装RAGTool和MemoryTool的调用逻辑
2. Gradio Web界面:提供友好的用户交互界面,这个部分可以参考示例代码学习
3. 其他核心功能:笔记记录、学习回顾、统计查看和报告生成
### 8.4.2 核心助手类的实现
首先,我们实现核心的助手类`PDFLearningAssistant`,它封装了RAGTool和MemoryTool的调用逻辑。
(1)类的初始化
```python
class PDFLearningAssistant:
"""智能文档问答助手"""
def __init__(self, user_id: str = "default_user"):
"""初始化学习助手
Args:
user_id: 用户ID,用于隔离不同用户的数据
"""
self.user_id = user_id
self.session_id = f"session_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
# 初始化工具
self.memory_tool = MemoryTool(user_id=user_id)
self.rag_tool = RAGTool(rag_namespace=f"pdf_{user_id}")
# 学习统计
self.stats = {
"session_start": datetime.now(),
"documents_loaded": 0,
"questions_asked": 0,
"concepts_learned": 0
}
# 当前加载的文档
self.current_document = None
```
在这个初始化过程中,我们做了几个关键的设计决策:
MemoryTool的初始化:通过`user_id`参数实现用户级别的记忆隔离。不同用户的学习记忆是完全独立的,每个用户都有自己的工作记忆、情景记忆、语义记忆和感知记忆空间。
RAGTool的初始化:通过`rag_namespace`参数实现知识库的命名空间隔离。使用`f"pdf_{user_id}"`作为命名空间,每个用户都有自己独立的PDF知识库。
会话管理:`session_id`用于追踪单次学习会话的完整过程,便于后续的学习历程回顾和分析。
统计信息:`stats`字典记录关键的学习指标,用于生成学习报告。
(2)加载PDF文档
```python
def load_document(self, pdf_path: str) -> Dict[str, Any]:
"""加载PDF文档到知识库
Args:
pdf_path: PDF文件路径
Returns:
Dict: 包含success和message的结果
"""
if not os.path.exists(pdf_path):
return {"success": False, "message": f"文件不存在: {pdf_path}"}
start_time = time.time()
# 【RAGTool】处理PDF: MarkItDown转换 → 智能分块 → 向量化
result = self.rag_tool.execute(
"add_document",
file_path=pdf_path,
chunk_size=1000,
chunk_overlap=200
)
process_time = time.time() - start_time
if result.get("success", False):
self.current_document = os.path.basename(pdf_path)
self.stats["documents_loaded"] += 1
# 【MemoryTool】记录到学习记忆
self.memory_tool.execute(
"add",
content=f"加载了文档《{self.current_document}》",
memory_type="episodic",
importance=0.9,
event_type="document_loaded",
session_id=self.session_id
)
return {
"success": True,
"message": f"加载成功!(耗时: {process_time:.1f}秒)",
"document": self.current_document
}
else:
return {
"success": False,
"message": f"加载失败: {result.get('error', '未知错误')}"
}
```
我们通过一行代码就能完成PDF的处理:
```python
result = self.rag_tool.execute(
"add_document",
file_path=pdf_path,
chunk_size=1000,
chunk_overlap=200
)
```
这个调用会触发RAGTool的完整处理流程(MarkItDown转换、增强处理、智能分块、向量化存储),这些内部细节在8.3节已经详细介绍过。我们只需要关注:
- 操作类型:`"add_document"` - 添加文档到知识库
- 文件路径:`file_path` - PDF文件的路径
- 分块参数:`chunk_size=1000, chunk_overlap=200` - 控制文本分块
- 返回结果:包含处理状态和统计信息的字典
文档加载成功后,我们使用MemoryTool记录到情景记忆:
```python
self.memory_tool.execute(
"add",
content=f"加载了文档《{self.current_document}》",
memory_type="episodic",
importance=0.9,
event_type="document_loaded",
session_id=self.session_id
)
```
为什么用情景记忆? 因为这是一个具体的、有时间戳的事件,适合用情景记忆记录。`session_id`参数将这个事件关联到当前学习会话,便于后续回顾学习历程。
这个记忆记录为后续的个性化服务奠定了基础:
- 用户询问"我之前加载过哪些文档?" → 从情景记忆中检索
- 系统可以追踪用户的学习历程和文档使用情况
### 8.4.3 智能问答功能
文档加载完成后,用户就可以向文档提问了。我们实现一个`ask`方法来处理用户的问题:
```python
def ask(self, question: str, use_advanced_search: bool = True) -> str:
"""向文档提问
Args:
question: 用户问题
use_advanced_search: 是否使用高级检索(MQE + HyDE)
Returns:
str: 答案
"""
if not self.current_document:
return "⚠️ 请先加载文档!"
# 【MemoryTool】记录问题到工作记忆
self.memory_tool.execute(
"add",
content=f"提问: {question}",
memory_type="working",
importance=0.6,
session_id=self.session_id
)
# 【RAGTool】使用高级检索获取答案
answer = self.rag_tool.execute(
"ask",
question=question,
limit=5,
enable_advanced_search=use_advanced_search,
enable_mqe=use_advanced_search,
enable_hyde=use_advanced_search
)
# 【MemoryTool】记录到情景记忆
self.memory_tool.execute(
"add",
content=f"关于'{question}'的学习",
memory_type="episodic",
importance=0.7,
event_type="qa_interaction",
session_id=self.session_id
)
self.stats["questions_asked"] += 1
return answer
```
当我们调用`self.rag_tool.execute("ask", ...)`时,RAGTool内部执行了以下高级检索流程:
1. 多查询扩展(MQE):
```python
# 生成多样化查询
expanded_queries = self._generate_multi_queries(question)
# 例如,对于"什么是大语言模型?",可能生成:
# - "大语言模型的定义是什么?"
# - "请解释一下大语言模型"
# - "LLM是什么意思?"
```
MQE通过LLM生成语义等价但表述不同的查询,从多个角度理解用户意图,提升召回率30%-50%。
2. 假设文档嵌入(HyDE):
- 生成假设答案文档,桥接查询和文档的语义鸿沟
- 使用假设答案的向量进行检索
这些高级检索技术的内部实现在8.3.5节已经详细介绍过。
### 8.4.4 其他核心功能
除了加载文档和智能问答,我们还需要实现笔记记录、学习回顾、统计查看和报告生成等功能:
```python
def add_note(self, content: str, concept: Optional[str] = None):
"""添加学习笔记"""
self.memory_tool.execute(
"add",
content=content,
memory_type="semantic",
importance=0.8,
concept=concept or "general",
session_id=self.session_id
)
self.stats["concepts_learned"] += 1
def recall(self, query: str, limit: int = 5) -> str:
"""回顾学习历程"""
result = self.memory_tool.execute(
"search",
query=query,
limit=limit
)
return result
def get_stats(self) -> Dict[str, Any]:
"""获取学习统计"""
duration = (datetime.now() - self.stats["session_start"]).total_seconds()
return {
"会话时长": f"{duration:.0f}秒",
"加载文档": self.stats["documents_loaded"],
"提问次数": self.stats["questions_asked"],
"学习笔记": self.stats["concepts_learned"],
"当前文档": self.current_document or "未加载"
}
def generate_report(self, save_to_file: bool = True) -> Dict[str, Any]:
"""生成学习报告"""
memory_summary = self.memory_tool.execute("summary", limit=10)
rag_stats = self.rag_tool.execute("stats")
duration = (datetime.now() - self.stats["session_start"]).total_seconds()
report = {
"session_info": {
"session_id": self.session_id,
"user_id": self.user_id,
"start_time": self.stats["session_start"].isoformat(),
"duration_seconds": duration
},
"learning_metrics": {
"documents_loaded": self.stats["documents_loaded"],
"questions_asked": self.stats["questions_asked"],
"concepts_learned": self.stats["concepts_learned"]
},
"memory_summary": memory_summary,
"rag_status": rag_stats
}
if save_to_file:
report_file = f"learning_report_{self.session_id}.json"
with open(report_file, 'w', encoding='utf-8') as f:
json.dump(report, f, ensure_ascii=False, indent=2, default=str)
report["report_file"] = report_file
return report
```
这些方法分别实现了:
- add_note:将学习笔记保存到语义记忆
- recall:从记忆系统中检索学习历程
- get_stats:获取当前会话的统计信息
- generate_report:生成详细的学习报告并保存为JSON文件
### 8.4.5 运行效果展示
接下来是运行效果展示,如图8.7所示,进入主页面后需要先初始化助手,也就是加载我们的数据库,模型,API之类的载入操作。后传入PDF文档,并点击加载文档。
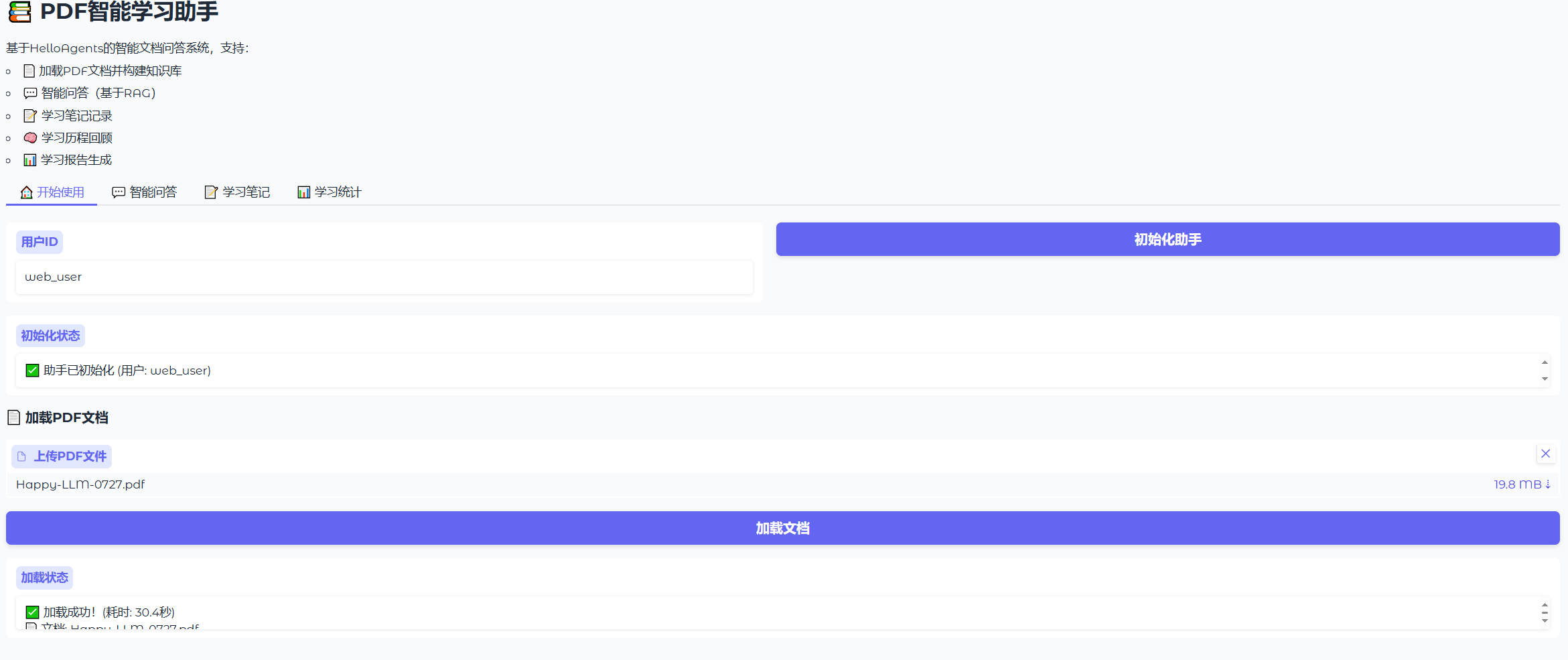
图 8.7 问答助手主页面
第一个功能是智能问答,将可以基于上传的文档进行检索,并返回参考来源和相关资料的相似度计算,这是RAG tool能力的体现,如图8.8所示。
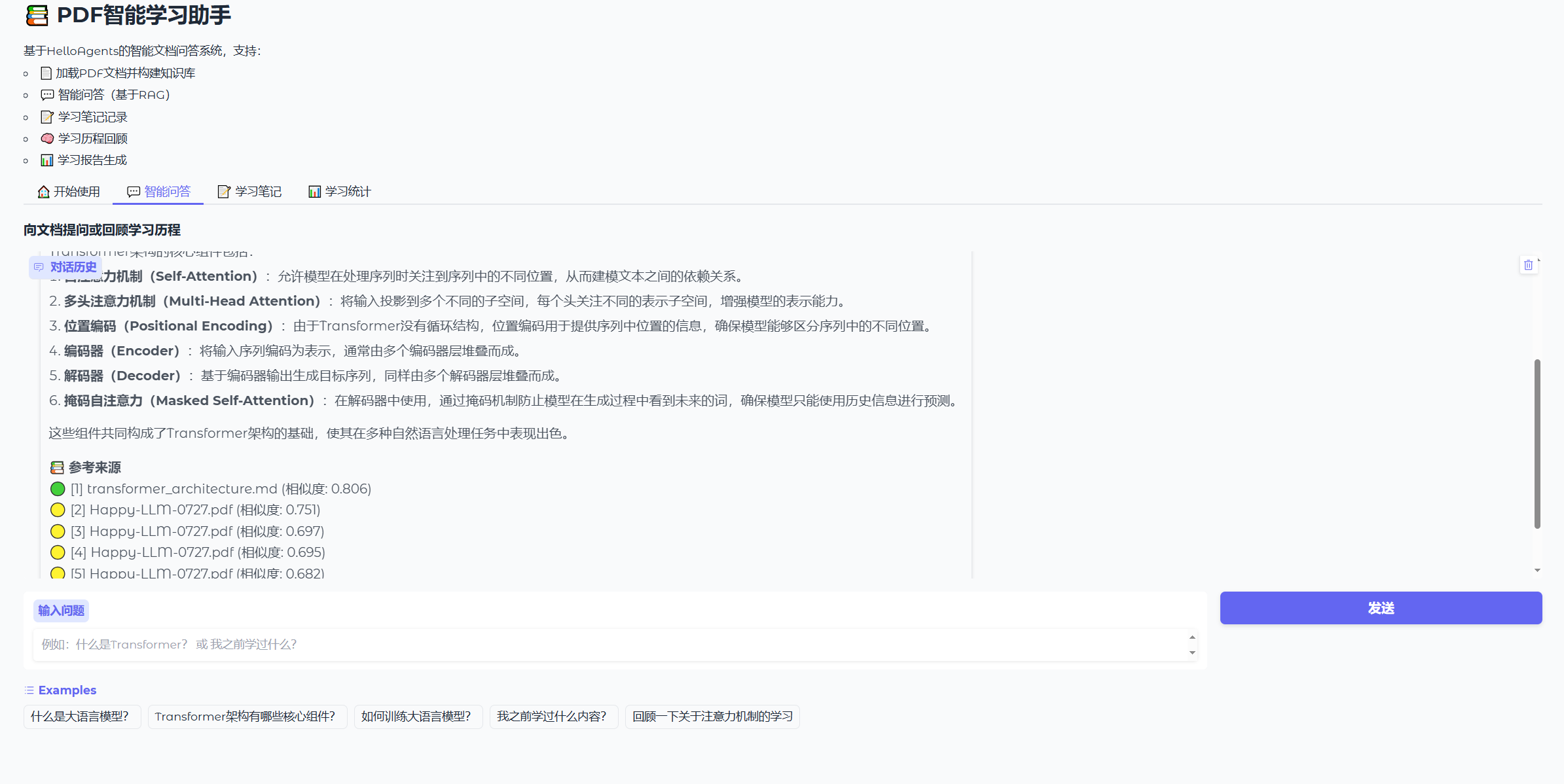
图 8.8 问答助手主页面
第二个功能是学习笔记,如图8.9所示,可以对于相关概念进行勾选,以及撰写笔记内容,这一部分运用到Memory tool,将会存放你的个人笔记在数据库内,方便统计和后续返回整体的学习报告。
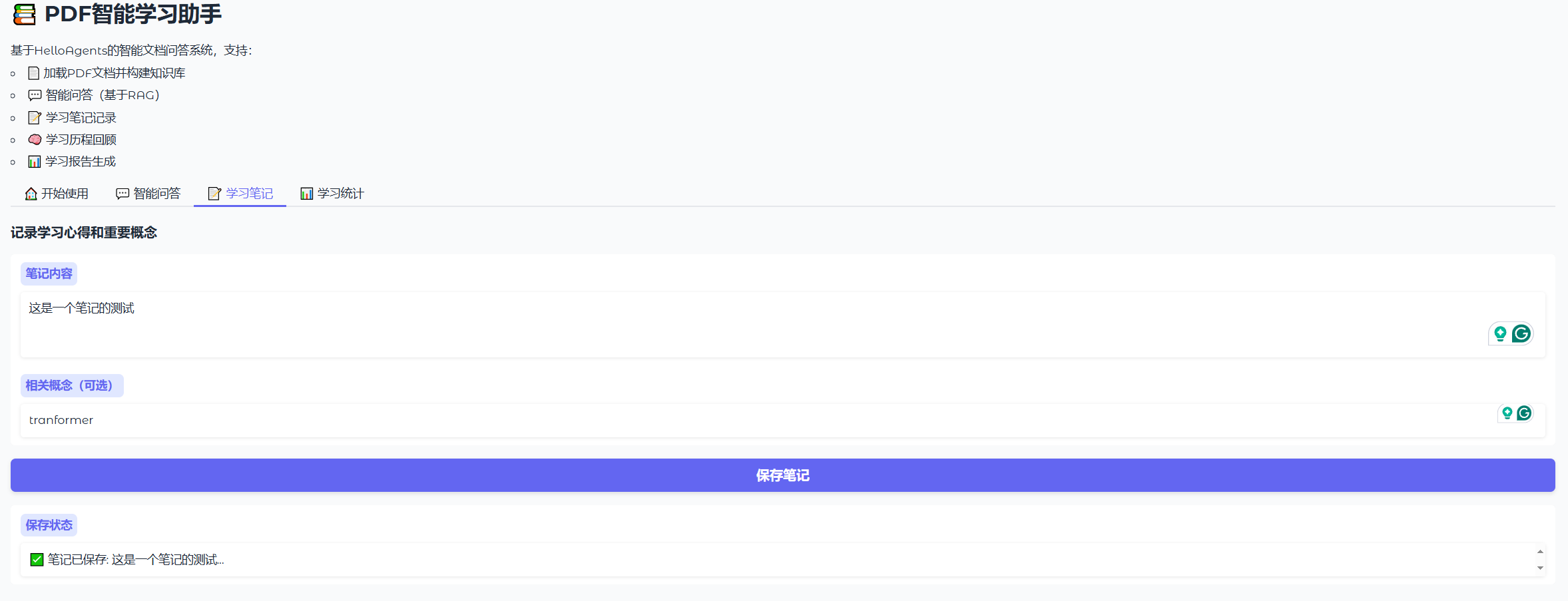
图 8.9 问答助手主页面
最后是学习进度的统计和报告的生成,如图8.10所示,我们将可以看到使用助手期间加载的文档数量,提问次数,和笔记数量,最终将我们的问答结果和笔记整理为一个JSON文档返回。
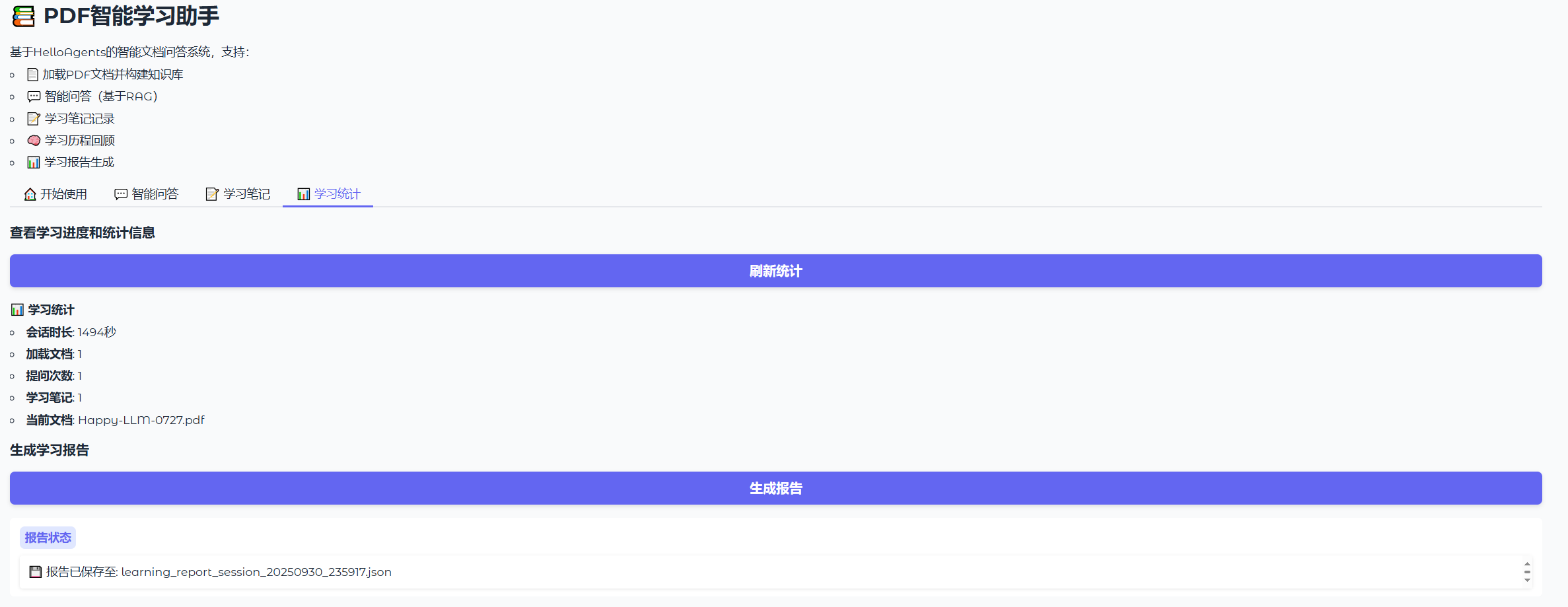
图 8.10 问答助手主页面
通过这个问答助手的案例,我们展示了如何使用RAGTool和MemoryTool构建一个完整的基于Web的智能文档问答系统。完整的代码可以在`code/chapter8/11_Q&A_Assistant.py`中找到。启动后访问 `http://localhost:7860` 即可使用这个智能学习助手。
建议读者亲自运行这个案例,体验RAG和Memory的能力,并在此基础上进行扩展和定制,构建符合自己需求的智能应用!
## 8.5 本章总结与展望
在本章中,我们成功地为HelloAgents框架增加了两个核心能力:记忆系统和RAG系统。
对于希望深入学习和应用本章内容的读者,我们提供以下建议:
1. 从零到一,亲手设计一个基础记忆模块,并逐步迭代,为其增添更复杂的特性。
2. 在项目中尝试并评估不同的嵌入模型与检索策略,寻找特定任务下的最优解。
3. 将所学的记忆与 RAG 系统应用于一个真实的个人项目,在实战中检验和提升能力。
进阶探索
1. 跟踪并研究前沿memory,rag仓库,学习优秀实现。
2. 探索将 RAG 架构应用于多模态(文本+图像)或跨模态场景的可能性。
3. 参与HelloAgents开源项目,贡献自己的想法和代码
通过本章的学习,您不仅掌握了Memory和RAG系统的实现技术,更重要的是理解了如何将认知科学理论转化为实际的工程解决方案。这种跨学科的思维方式,将为您在AI领域的进一步发展奠定坚实的基础。
最后,让我们通过一个思维导图来总结本章的完整知识体系,如图8.11所示:
图 8.11 Hello-agents第八章知识总结
本章展示了HelloAgents框架记忆系统和RAG技术的能力,我们成功构建了一个具有真正"智能"的学习助手。这种架构可以轻松扩展到其他应用场景,如客户服务、技术支持、个人助理等领域。
在下一章中,我们将继续探索如何通过上下文工程进一步提升智能体的对话质量和用户体验,敬请期待!
## 参考文献
[1] Atkinson, R. C., & Shiffrin, R. M. (1968). Human memory: A proposed system and its control processes. In *Psychology of learning and motivation* (Vol. 2, pp. 89-195). Academic press.